Textual content-to-SQL applied sciences often battle to seize the entire context and which means of a person’s request, leading to queries that don’t precisely match the meant. Whereas builders work laborious to boost these programs, it’s price questioning if there’s a higher technique.
Enter RAG-to-SQL—a brand new strategy that mixes pure language understanding with highly effective knowledge retrieval to generate correct SQL queries. By mixing the most effective of pure language processing and data retrieval, RAG-to-SQL presents a extra dependable approach to flip on a regular basis language into significant insights out of your database.
On this article, we’ll discover how RAG-to-SQL can rework the way in which we work together with databases, particularly utilizing Google Cloud providers similar to BigQuery and Vertex AI.
Studying Goals
- Determine the restrictions of Textual content-to-SQL programs in precisely capturing person intent.
- Perceive the benefits of RAG-to-SQL as a brand new paradigm for producing extra dependable SQL queries.
- Implement the RAG-to-SQL strategy utilizing Google Cloud providers like BigQuery and Vertex AI.
- Learn to combine and make the most of a number of Google Cloud instruments for RAG-to-SQL implementation.
This text was revealed as part of the Information Science Blogathon.
Limitations of Conventional Textual content-to-SQL Approaches
The principle thought behind textual content to sql fashions of LLM was to allow individuals who have no idea about SQL to work together with database and acquire info utilizing pure language as an alternative. The prevailing textual content 2 sql framework depends primarily in LLM information to have the ability to convert pure language question to sql question. This will result in unsuitable or invalid formulation of SQL queries. That is the place the brand new strategy RAG to SQL involves our rescue which is defined in subsequent part.
What’s RAG-to-SQL ?
As a way to overcome the shortcomings of Textual content to SQL we are able to use the revolutionary strategy of RAG to SQL. The combination of area details about the database is the main problem that every text-to-SQL software program faces. The RAG2SQL structure addresses this problem by including contextual knowledge (metadata, DDL, queries, and extra). This knowledge is then “educated” and made accessible for utilization.
Moreover, the “retriever” evaluates and forwards essentially the most related context to answer the Person Question. The tip result’s enormously improved precision.
Setting Up RAG-to-SQL with Google Cloud: A Step-by-Step Information
Observe an in depth information to implement RAG-to-SQL utilizing Google Cloud providers similar to BigQuery and Vertex AI.
Pre-requisites for Code
As a way to comply with and run this code you will want to setup your GCP (google cloud account with Fee info). Initially they supply free 300$ trial for 90 days so no expenses might be incurred. Element for account setup : Hyperlink
Code Flowchart
Under is the code flowchart which describes at the next degree the assorted blocks of code. We will refer it to comply with alongside as we proceed.
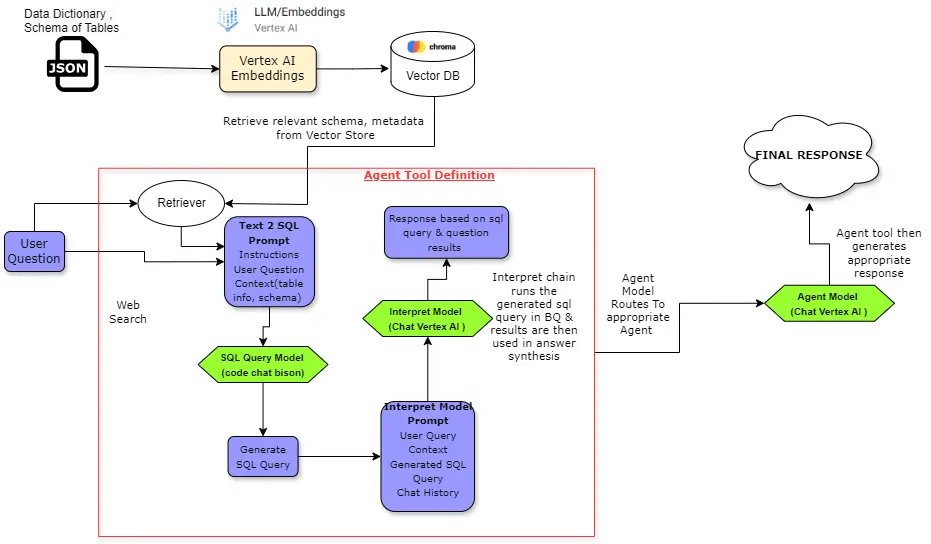
The code implementation could be divided into 3 main blocks :
- SQL Question Chain: This chain is liable for producing acceptable sql question primarily based on person query and related schema of desk fetched from Vector DB.
- Interpret Chain: This chain takes the SQL question from the earlier chain, runs it in BigQuery, after which makes use of the outcomes to generate a response with an acceptable immediate.
- Agent Chain: That is the ultimate chain which encapsulates the above two chains. Each time a person query is available in it’ll determine whether or not to name sql question device or reply the query instantly. It routes person queries to varied instruments primarily based on the duty required to reply the query.
Step 1: Putting in the Required Libraries
In colab pocket book we’ve got to put in the beneath libraries required for this implementation.
! pip set up langchain==0.0.340 --quiet
! pip set up chromadb==0.4.13 --quiet
! pip set up google-cloud-bigquery[pandas] --quiet
! pip set up google-cloud-aiplatform --quiet#import csvStep 2: Configuring Your Google Cloud Mission and Credentials
Now we’ve got to declare some variables to initialise our GCP venture and Massive Question Datasets . Utilizing this variables we are able to entry the tables in Massive Question withing GCP in our pocket book.
You possibly can view this particulars in your GCP cloud console. In BigQuery you’ll be able to create a dataset and inside dataset you’ll be able to add or add a desk for particulars see Create Dataset and Create Desk.
VERTEX_PROJECT = "Your GCP Mission ID" # @param{kind: "string"}
VERTEX_REGION = "us-central1" # @param{kind: "string"}
BIGQUERY_DATASET = "Massive Question Dataset Title" # @param{kind: "string"}
BIGQUERY_PROJECT = "Vertex Mission ID" # @param{kind: "string"}Now authenticate and login to your GCP Vertex AI out of your pocket book utilizing beneath code in colab.
from google.colab import auth
auth.authenticate_user()
import vertexai
vertexai.init(venture=VERTEX_PROJECT, location=VERTEX_REGION)Step 3: Constructing a Vector Database for Desk Schema Storage
Now we’ve got to create a vector db which can comprise schema of varied tables current in our dataset and we’ll create a retriever on high of this vector db in order that we are able to incorporate RAG in our workflow.
Connecting to Massive Question utilizing BQ consumer in python and fetching schema of tables.
from google.cloud import bigquery
import json
#Fetching Schemas of Tables
bq_client = bigquery.Consumer(venture=VERTEX_PROJECT)
bq_tables = bq_client.list_tables(dataset=f"{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}")
schemas = []
for bq_table in bq_tables:
t = bq_client.get_table(f"{BIGQUERY_PROJECT}.{BIGQUERY_DATASET}.{bq_table.table_id}")
schema_fields = [f.to_api_repr() for f in t.schema]
schema = f"The schema for desk {bq_table.table_id} is the next: n```{json.dumps(schema_fields, indent=1)}```"
schemas.append(schema)
print(f"Discovered {len(schemas)} tables in dataset {BIGQUERY_PROJECT}:{BIGQUERY_DATASET}")#import csvStoring the schemas in Vector Db similar to Chroma DB. We have to create a folder known as “knowledge”
from langchain.embeddings import VertexAIEmbeddings
from langchain.vectorstores import Chroma
embeddings = VertexAIEmbeddings()
strive: # Keep away from duplicated paperwork
vector_store.delete_collection()
besides:
print("No want to wash the vector retailer")
vector_store = Chroma.from_texts(schemas, embedding=embeddings,persist_directory='./knowledge')
n_docs = len(vector_store.get()['ids'])
retriever = vector_store.as_retriever(search_kwargs={'ok': 2})
print(f"The vector retailer has {n_docs} paperwork")Step 4: Instantiating LLM Fashions for SQL Question, Interpretation, and Agent Chains
We’ll instantiate the three LLM fashions for the three totally different chains.
First mannequin is Question Mannequin which is liable for producing SQL question primarily based on person query and desk schema retrieved from vector db just like person query. For this we’re utilizing “codechat-bison” mannequin . This mannequin makes a speciality of producing code in several coding languages and therefore, is acceptable for our use case.
Different 2 fashions are default LLM fashions in ChatVertexAI which is “gemini-1.5-flash-001” that is the most recent gemini mannequin optimized for chat and fast response.
from langchain.chat_models import ChatVertexAI
from langchain.llms import VertexAI
query_model = ChatVertexAI(model_name="codechat-bison", max_output_tokens=1000)
interpret_data_model = ChatVertexAI(max_output_tokens=1000)
agent_model = ChatVertexAI(max_output_tokens=1024)Step 5: Setting up the SQL Question Chain
Under is the SQL immediate used to generate the SQL question for the enter person query.
SQL_PROMPT = """You're a SQL and BigQuery skilled.
Your job is to create a question for BigQuery in SQL.
The next paragraph comprises the schema of the desk used for a question. It's encoded in JSON format.
{context}
Create a BigQuery SQL question for the next person enter, utilizing the above desk.
And Use solely columns talked about in schema for the SQL question
The person and the agent have carried out this dialog up to now:
{chat_history}
Observe these restrictions strictly:
- Solely return the SQL code.
- Don't add backticks or any markup. Solely write the question as output. NOTHING ELSE.
- In FROM, at all times use the total desk path, utilizing `{venture}` as venture and `{dataset}` as dataset.
- At all times rework nation names to full uppercase. As an example, if the nation is Japan, you need to use JAPAN within the question.
Person enter: {query}
SQL question:
"""Now we’ll outline a perform which can retrieve related paperwork i.e schemas for the person query enter.
from langchain.schema.vectorstore import VectorStoreRetriever
def get_documents(retriever: VectorStoreRetriever, query: str) -> str:
# Return solely the primary doc
output = ""
for d in retriever.get_relevant_documents(query):
output += d.page_content
output += "n"
return outputThen we outline the LLM chain utilizing Langchain expression language syntax. Word we outline immediate with 5 placeholder variables and later we outline a partial immediate by filling within the 2 placeholder variables venture and dataset. The remainder of the variables will get populated with incoming request dictionary consisting of enter, chat historical past and the context variable is populated type the perform we outlined above get_documents.
from operator import itemgetter
from langchain.prompts import PromptTemplate
from langchain.schema import StrOutputParser
prompt_template = PromptTemplate(
input_variables=["context", "chat_history", "question", "project", "dataset"],
template=SQL_PROMPT)
partial_prompt = prompt_template.partial(venture=BIGQUERY_PROJECT,
dataset=BIGQUERY_DATASET)
# Enter might be like {"enter": "SOME_QUESTION", "chat_history": "HISTORY"}
docs = {"context": lambda x: get_documents(retriever, x['input'])}
query = {"query": itemgetter("enter")}
chat_history = {"chat_history": itemgetter("chat_history")}
query_chain = docs | query | chat_history | partial_prompt | query_model
question = query_chain | StrOutputParser()
Allow us to check our chain utilizing CallBack Handler of Langchain which can present every steps of chain execution intimately.
from langchain.callbacks.tracers import ConsoleCallbackHandler
# Instance
x = {"enter": "Highest length of journey the place begin station was from Atlantic Ave & Fort Greene Pl ", "chat_history": ""}
print(question.invoke(x, config={'callbacks': [ConsoleCallbackHandler()]}))

Step 6: Refining the SQL Chain Output for Interpretation
We have to refine the above sql chain output so that it’ll embrace different variables too in its outp which might be then handed on to second chain – interpret chain.
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
from langchain.schema.runnable import RunnableLambda
#Refine the Chain output to incorporate different variables in output in dictionary format
def _dict_to_json(x: dict) -> str:
return "```n" + json.dumps(x) + "n```"
query_response_schema = [
ResponseSchema(name="query", description="SQL query to solve the user question."),
ResponseSchema(name="question", description="Question asked by the user."),
ResponseSchema(name="context", description="Documents retrieved from the vector store.")
]
query_output_parser = StructuredOutputParser.from_response_schemas(query_response_schema)
query_output_json = docs | query | {"question": question} | RunnableLambda(_dict_to_json) | StrOutputParser()
query_output = query_output_json | query_output_parserLets attempt to execute this chain.
# Instance
x = {"enter": "Give me high 2 begin stations the place journey length was highest?", "chat_history": ""}
output = query_output.invoke(x) # Output is now a dictionary, enter for the following chain
Above we are able to see the output of the refined chain is an sql question.
Step 7: Constructing the Interpret Chain for Question Outcomes
Now we’ve got to construct the following chain which can take output of SQL question chain outlined above. This chain will take the sql question from earlier chain and run it in Massive Question and its outcomes are then used to generate a response utilizing acceptable immediate.
INTERPRET_PROMPT = """You're a BigQuery skilled. You might be additionally skilled in extracting knowledge from CSV.
The next paragraph describes the schema of the desk used for a question. It's encoded in JSON format.
{context}
A person requested this query:
{query}
To search out the reply, the next SQL question was run in BigQuery:
```
{question}
```
The results of that question was the next desk in CSV format:
```
{outcome}
```
Primarily based on these outcomes, present a short reply to the person query.
Observe these restrictions strictly:
- Don't add any rationalization about how the reply is obtained, simply write the reply.
- Extract any worth associated to the reply solely from the results of the question. Don't use another knowledge supply.
- Simply write the reply, omit the query out of your reply, it is a chat, simply present the reply.
- Should you can not discover the reply within the outcome, don't make up any knowledge, simply say "I can not discover the reply"
"""from google.cloud import bigquery
def get_bq_csv(bq_client: bigquery.Consumer, question: str) -> str:
cleaned_query = clean_query(question)
df = bq_client.question(cleaned_query, location="US").to_dataframe()
return df.to_csv(index=False)
def clean_query(question: str):
question = question.substitute("```sql","")
cleaned_query = question.substitute("```","")
return cleaned_queryWe’ll outline two perform one is clean_query – it will clear the sql question of apostrophes and different pointless characters and different is get_bq_csv – it will run the cleaned sql question in Massive Question and get the output desk in csv format.
# Get the output of the earlier chain
question = {"question": itemgetter("question")}
context = {"context": itemgetter("context")}
query = {"query": itemgetter("query")}
#cleaned_query = {"outcome": lambda x: clean_query(x["query"])}
query_result = {"outcome": lambda x: get_bq_csv(bq_client, x["query"])}
immediate = PromptTemplate(
input_variables=["question", "query", "result", "context"],
template=INTERPRET_PROMPT)
run_bq_chain = context | query | question | query_result | immediate
run_bq_result = run_bq_chain | interpret_data_model | StrOutputParser()
Let’s execute the chain and check it.
# Instance
x = {"enter": "Give me high 2 begin stations the place journey length was highest?", "chat_history": ""}
final_response = run_bq_result.invoke(query_output.invoke(x))
print(final_response)
Step 8: Implementing the Agent Chain for Dynamic Question Routing
Now we’ll construct the ultimate chain which is the Agent Chain . When a person asks a query, it decides whether or not to utilise the SQL question device or to reply it instantly. Mainly, it sends person queries to varied instruments in accordance on the work that have to be accomplished so as to reply the person’s inquiry.
We outline an agent_memory, agent immediate, device funtion.
from langchain.reminiscence import ConversationBufferWindowMemory
agent_memory = ConversationBufferWindowMemory(
memory_key="chat_history",
ok=10,
return_messages=True)AGENT_PROMPT = """You're a very highly effective assistant that may reply questions utilizing BigQuery.
You possibly can invoke the device user_question_tool to reply questions utilizing BigQuery.
At all times use the instruments to attempt to reply the questions. Use the chat historical past for context. By no means attempt to use another exterior info.
Assume that the person might write with misspellings, repair the spelling of the person earlier than passing the query to any device.
Do not point out what device you have got utilized in your reply.
"""from langchain.instruments import device
from langchain.callbacks.tracers import ConsoleCallbackHandler
@device
def user_question_tool(query) -> str:
"""Helpful to reply pure language questions from customers utilizing BigQuery."""
config={'callbacks': [ConsoleCallbackHandler()]}
config = {}
reminiscence = agent_memory.buffer_as_str.strip()
query = {"enter": query, "chat_history": reminiscence}
question = query_output.invoke(query, config=config)
print("nn******************nn")
print(question['query'])
print("nn******************nn")
outcome = run_bq_result.invoke(question, config=config)
return outcome.strip()
We now deliver collectively all the principle elements of agent and initialize the agent.
from langchain.brokers import AgentType, initialize_agent, AgentExecutor
agent_kwgards = {"system_message": AGENT_PROMPT}
agent_tools = [user_question_tool]
agent_memory.clear()
agent = initialize_agent(
instruments=agent_tools,
llm=agent_model,
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION,
reminiscence=agent_memory,
agent_kwgards=agent_kwgards,
max_iterations=5,
early_stopping_method='generate',
verbose=True)Lets run the agent now.
q = "Give me high 2 begin stations the place journey length was highest?"
agent.invoke(q)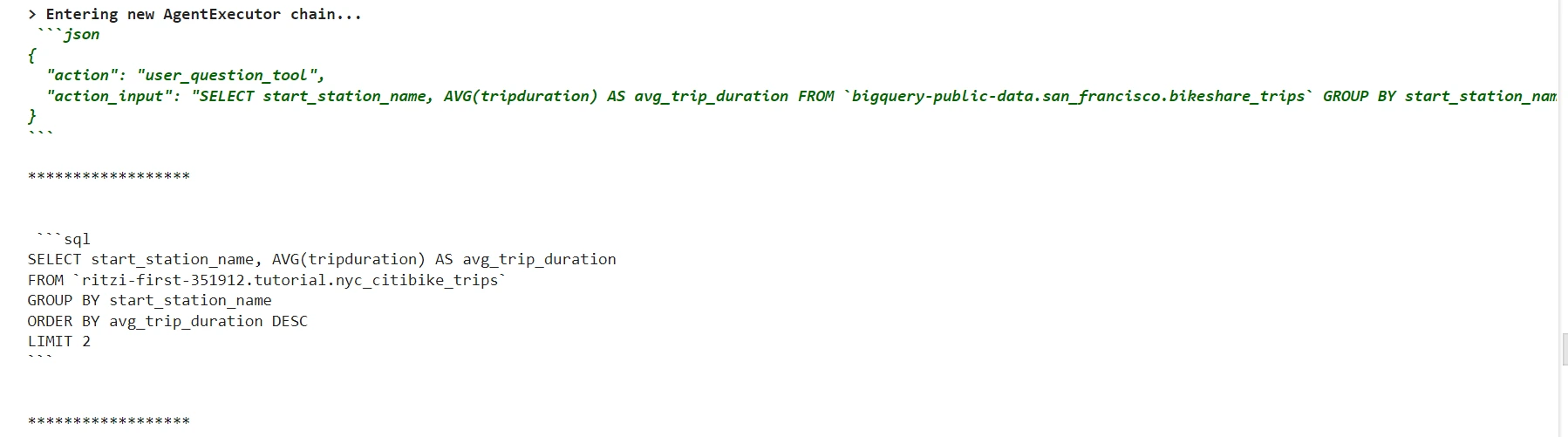

Observe-up query to agent.
q = "What's the capability for every of those station identify?"
agent.invoke(q)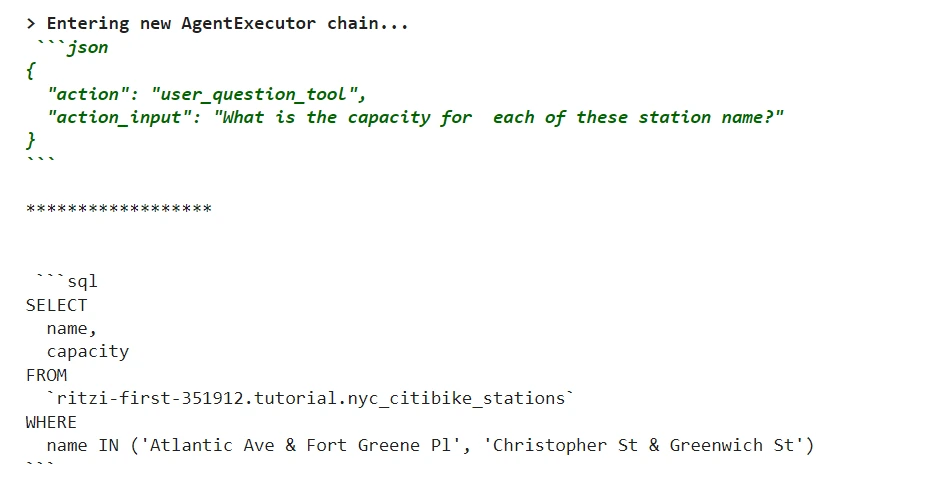

Observations
The agent was precisely capable of course of the advanced query and in addition generate appropriate solutions for comply with -up query primarily based on chat historical past after which it utilised one other desk to get capability info of citi bikes.
Conclusion
The RAG-to-SQL strategy represents a big development in addressing the restrictions of conventional Textual content-to-SQL fashions by incorporating contextual knowledge and leveraging retrieval strategies. This system enhances question accuracy by retrieving related schema info from vector databases, permitting for extra exact SQL era. Implementing RAG-to-SQL inside Google Cloud providers like BigQuery and Vertex AI demonstrates its scalability and effectiveness in real-world purposes. By automating the decision-making course of in question dealing with, RAG-to-SQL opens new prospects for non-technical customers to work together seamlessly with databases whereas sustaining excessive precision.
Key Takeaways
- Overcomes Textual content-to-SQL Limitations addresses the frequent pitfalls of conventional Textual content-to-SQL fashions by integrating metadata.
- The agent-based system effectively decides the way to course of person queries, bettering usability.
- RAG-to-SQL permits non-technical customers to generate advanced SQL queries with pure language inputs.
- The strategy is efficiently carried out utilizing providers like BigQuery and Vertex AI.
Incessantly Requested Questions
A. No, however you will get a trial interval of 90 days with 300$ credit if you happen to register first time and also you solely want to offer a card particulars for getting entry. No expenses are deducted from card and even if you happen to use any providers which is consuming past 300$ credit then Google will ask you to allow cost account to be able to use the service. So there isn’t a automated deduction of quantity.
A. This enables us to automate the desk schema which is to be fed to the LLM if we’re utilizing a number of tables we don’t must feed all desk schemas without delay . Primarily based on person question the related desk schema could be fetched from the RAG. Thus, rising effectivity over standard Textual content to SQL programs.
A. If we’re constructing a holistic chatbot it’d require lot of different instruments other than SQL question device . So we are able to leverage the agent and supply it with a number of instruments similar to net search , database sql question device, different rag instruments or perform calling api instruments. This may allow to deal with various kinds of person queries primarily based on the duty that must be completed to answer the person question.
The media proven on this article is just not owned by Analytics Vidhya and is used on the Creator’s discretion.