Think about driving via a tunnel in an autonomous automobile, however unbeknownst to you, a crash has stopped visitors up forward. Usually, you’d have to depend on the automotive in entrance of you to know it’s best to begin braking. However what in case your automobile may see across the automotive forward and apply the brakes even sooner?
Researchers from MIT and Meta have developed a pc imaginative and prescient approach that might sometime allow an autonomous automobile to do exactly that.
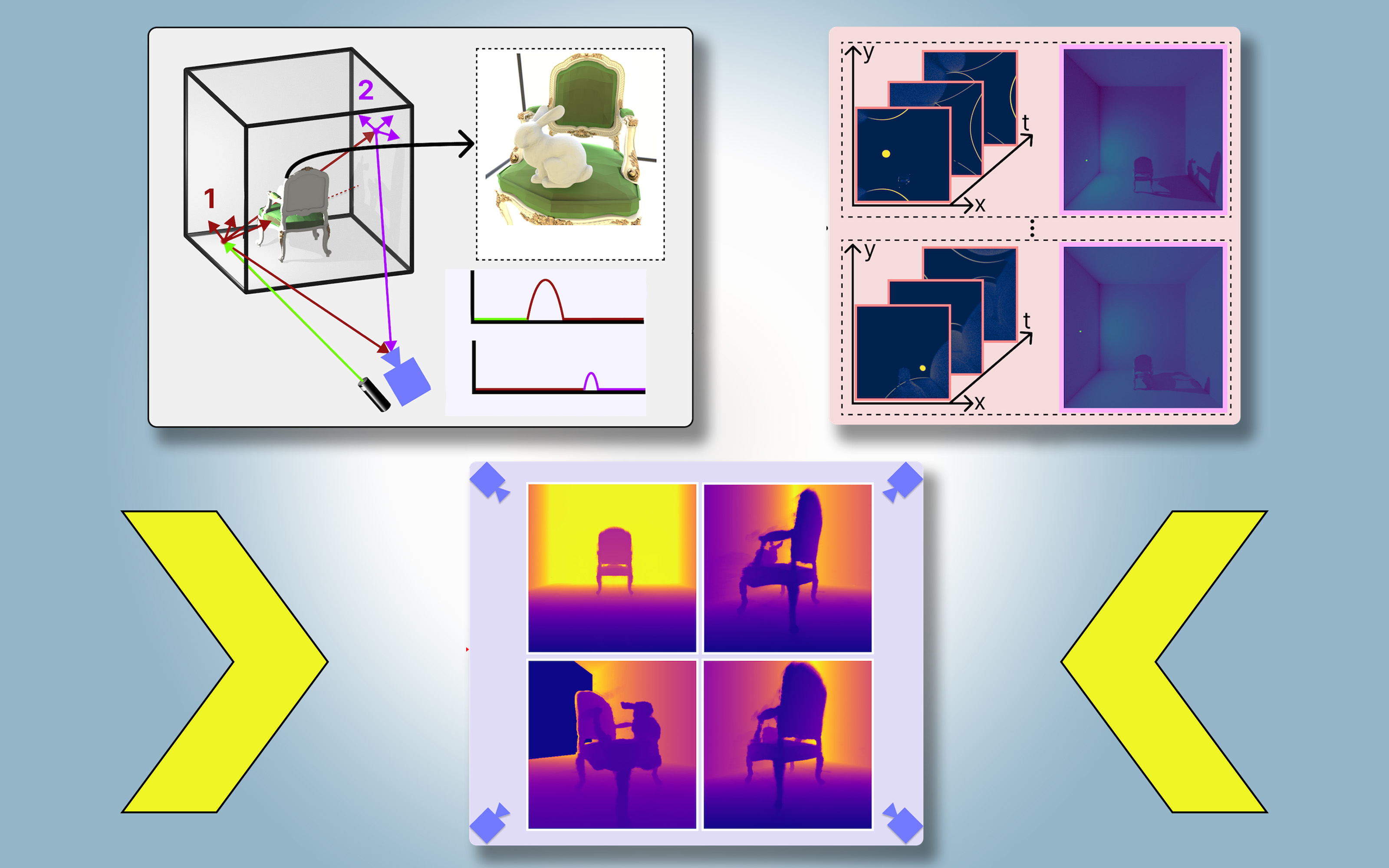
They’ve launched a technique that creates bodily correct, 3D fashions of a complete scene, together with areas blocked from view, utilizing photographs from a single digital camera place. Their approach makes use of shadows to find out what lies in obstructed parts of the scene.
They name their method PlatoNeRF, based mostly on Plato’s allegory of the cave, a passage from the Greek thinker’s “Republic” by which prisoners chained in a cave discern the fact of the surface world based mostly on shadows forged on the cave wall.
By combining lidar (mild detection and ranging) know-how with machine studying, PlatoNeRF can generate extra correct reconstructions of 3D geometry than some present AI methods. Moreover, PlatoNeRF is healthier at easily reconstructing scenes the place shadows are laborious to see, similar to these with excessive ambient mild or darkish backgrounds.
Along with bettering the protection of autonomous automobiles, PlatoNeRF may make AR/VR headsets extra environment friendly by enabling a consumer to mannequin the geometry of a room with out the necessity to stroll round taking measurements. It may additionally assist warehouse robots discover gadgets in cluttered environments quicker.
“Our key concept was taking these two issues which were completed in several disciplines earlier than and pulling them collectively — multibounce lidar and machine studying. It seems that once you convey these two collectively, that’s once you discover a number of new alternatives to discover and get the most effective of each worlds,” says Tzofi Klinghoffer, an MIT graduate scholar in media arts and sciences, analysis assistant within the Digicam Tradition Group of the MIT Media Lab, and lead writer of a paper on PlatoNeRF.
Klinghoffer wrote the paper along with his advisor, Ramesh Raskar, affiliate professor of media arts and sciences and chief of the Digicam Tradition Group at MIT; senior writer Rakesh Ranjan, a director of AI analysis at Meta Actuality Labs; in addition to Siddharth Somasundaram, a analysis assistant within the Digicam Tradition Group, and Xiaoyu Xiang, Yuchen Fan, and Christian Richardt at Meta. The analysis will probably be introduced on the Convention on Pc Imaginative and prescient and Sample Recognition.
Shedding mild on the issue
Reconstructing a full 3D scene from one digital camera viewpoint is a posh downside.
Some machine-learning approaches make use of generative AI fashions that attempt to guess what lies within the occluded areas, however these fashions can hallucinate objects that aren’t actually there. Different approaches try to infer the shapes of hidden objects utilizing shadows in a shade picture, however these strategies can wrestle when shadows are laborious to see.
For PlatoNeRF, the MIT researchers constructed off these approaches utilizing a brand new sensing modality referred to as single-photon lidar. Lidars map a 3D scene by emitting pulses of sunshine and measuring the time it takes that mild to bounce again to the sensor. As a result of single-photon lidars can detect particular person photons, they supply higher-resolution knowledge.
The researchers use a single-photon lidar to light up a goal level within the scene. Some mild bounces off that time and returns on to the sensor. Nonetheless, a lot of the mild scatters and bounces off different objects earlier than returning to the sensor. PlatoNeRF depends on these second bounces of sunshine.
By calculating how lengthy it takes mild to bounce twice after which return to the lidar sensor, PlatoNeRF captures further details about the scene, together with depth. The second bounce of sunshine additionally incorporates details about shadows.
The system traces the secondary rays of sunshine — those who bounce off the goal level to different factors within the scene — to find out which factors lie in shadow (as a consequence of an absence of sunshine). Based mostly on the placement of those shadows, PlatoNeRF can infer the geometry of hidden objects.
The lidar sequentially illuminates 16 factors, capturing a number of photographs which can be used to reconstruct the whole 3D scene.
“Each time we illuminate some extent within the scene, we’re creating new shadows. As a result of now we have all these completely different illumination sources, now we have a number of mild rays capturing round, so we’re carving out the area that’s occluded and lies past the seen eye,” Klinghoffer says.
A successful mixture
Key to PlatoNeRF is the mixture of multibounce lidar with a particular kind of machine-learning mannequin referred to as a neural radiance area (NeRF). A NeRF encodes the geometry of a scene into the weights of a neural community, which provides the mannequin a powerful potential to interpolate, or estimate, novel views of a scene.
This potential to interpolate additionally results in extremely correct scene reconstructions when mixed with multibounce lidar, Klinghoffer says.
“The most important problem was determining mix these two issues. We actually had to consider the physics of how mild is transporting with multibounce lidar and mannequin that with machine studying,” he says.
They in contrast PlatoNeRF to 2 frequent different strategies, one which solely makes use of lidar and the opposite that solely makes use of a NeRF with a shade picture.
They discovered that their methodology was in a position to outperform each methods, particularly when the lidar sensor had decrease decision. This might make their method extra sensible to deploy in the true world, the place decrease decision sensors are frequent in industrial gadgets.
“About 15 years in the past, our group invented the primary digital camera to ‘see’ round corners, that works by exploiting a number of bounces of sunshine, or ‘echoes of sunshine.’ These methods used particular lasers and sensors, and used three bounces of sunshine. Since then, lidar know-how has turn out to be extra mainstream, that led to our analysis on cameras that may see via fog. This new work makes use of solely two bounces of sunshine, which suggests the sign to noise ratio may be very excessive, and 3D reconstruction high quality is spectacular,” Raskar says.
Sooner or later, the researchers need to strive monitoring greater than two bounces of sunshine to see how that might enhance scene reconstructions. As well as, they’re interested by making use of extra deep studying methods and mixing PlatoNeRF with shade picture measurements to seize texture data.
“Whereas digital camera photographs of shadows have lengthy been studied as a way to 3D reconstruction, this work revisits the issue within the context of lidar, demonstrating vital enhancements within the accuracy of reconstructed hidden geometry. The work reveals how intelligent algorithms can allow extraordinary capabilities when mixed with atypical sensors — together with the lidar techniques that many people now carry in our pocket,” says David Lindell, an assistant professor within the Division of Pc Science on the College of Toronto, who was not concerned with this work.