Think about making an attempt to navigate by a whole bunch of pages in a dense doc full of tables, charts, and paragraphs. Discovering a selected determine or analyzing a pattern can be difficult sufficient for a human; now think about constructing a system to do it. Conventional doc retrieval techniques typically rely closely on textual content extraction, dropping essential context supplied by visuals just like the format of tables or steadiness sheets. What if as a substitute of counting on the normal method of OCR + format detection + chunking + textual content embedding, we immediately simply embed the entire web page in a doc capturing their full visible construction – tables, pictures, headings, and so on. It will be a groundbreaking shift, permitting the system to protect the wealthy context inside advanced paperwork. ColQwen, a sophisticated multimodal retrieval mannequin within the ColPali household, does simply that.
Studying Goal
- Perceive ColQwen, Multivector Embeddings, and Vespa.
- Put together monetary PDFs for retrieval by changing pages to pictures.
- Embed pages with ColQwen’s Imaginative and prescient Language Mannequin to generate multi-vector embeddings.
- Configure Vespa with an optimized schema and rating profile for environment friendly search.
- Construct a two-phase retrieval pipeline utilizing Vespa’s Hamming distance and MaxSim calculations.
- Visualize retrieved pages and discover ColQwen’s explainability options for interpretability.
What’s ColQwen?
ColQwen is a sophisticated multimodal retrieval mannequin that makes use of a Imaginative and prescient Language Mannequin (VLM) method that processes whole doc pages as pictures. Utilizing multi-vector embeddings it creates a richly layered illustration of the web page that maintains every web page’s construction and context. It’s constructed particularly to simplify and improve doc retrieval, particularly for visually dense paperwork.
Why ColQwen is Completely different?
Conventional techniques break down a doc to its fundamentals—OCR extracts the textual content, then splits, tags, and embeds it. Whereas this method works for text-only information, it limits the element retrievable from advanced paperwork the place format issues. In monetary studies or analysis papers, info resides not solely within the phrases but additionally of their visible construction—how headings, numbers, and summaries are positioned relative to 1 one other.
With ColQwen, the method is easy. As a substitute of decreasing pages to smaller textual content chunks, ColQwen’s multi-vector embeddings seize the entire web page picture, preserving each textual content and visible cues.
What’s Multivector embeddings?
💡We’ve been speaking about multi-vector embeddings, however what precisely are multi-vector embeddings, and the way are they used right here?
Not like conventional single-vector embeddings that use a single dense illustration for a whole doc, multi-vector embeddings create a number of, centered embeddings—one for every question token. Initially developed for fashions like ColBERT (for text-based retrieval with “late interplay”), multi-vector embeddings be sure that every question token can work together with probably the most related parts of a doc.
In ColQwen (and ColPali), this system is tailored for visually advanced paperwork. Every web page picture is split into patches, with every part—whether or not a desk, heading, or determine – receiving its personal embedding. When a question is made, every token within the question can search throughout these patches, surfacing probably the most related visible and textual elements of the web page. This fashion, ColQwen retrieves precisely the suitable content material, which is structured and contextually conscious.
Patches: In ColQwen, pictures are divided into small sections or “patches.” Every patch has its personal embedding, permitting the mannequin to deal with particular areas of a picture slightly than processing it as an entire. Patches are useful for breaking down visually advanced pages so that every half will be analyzed intimately.
Please examine the instance beneath to know MaxSim and late-interaction higher:
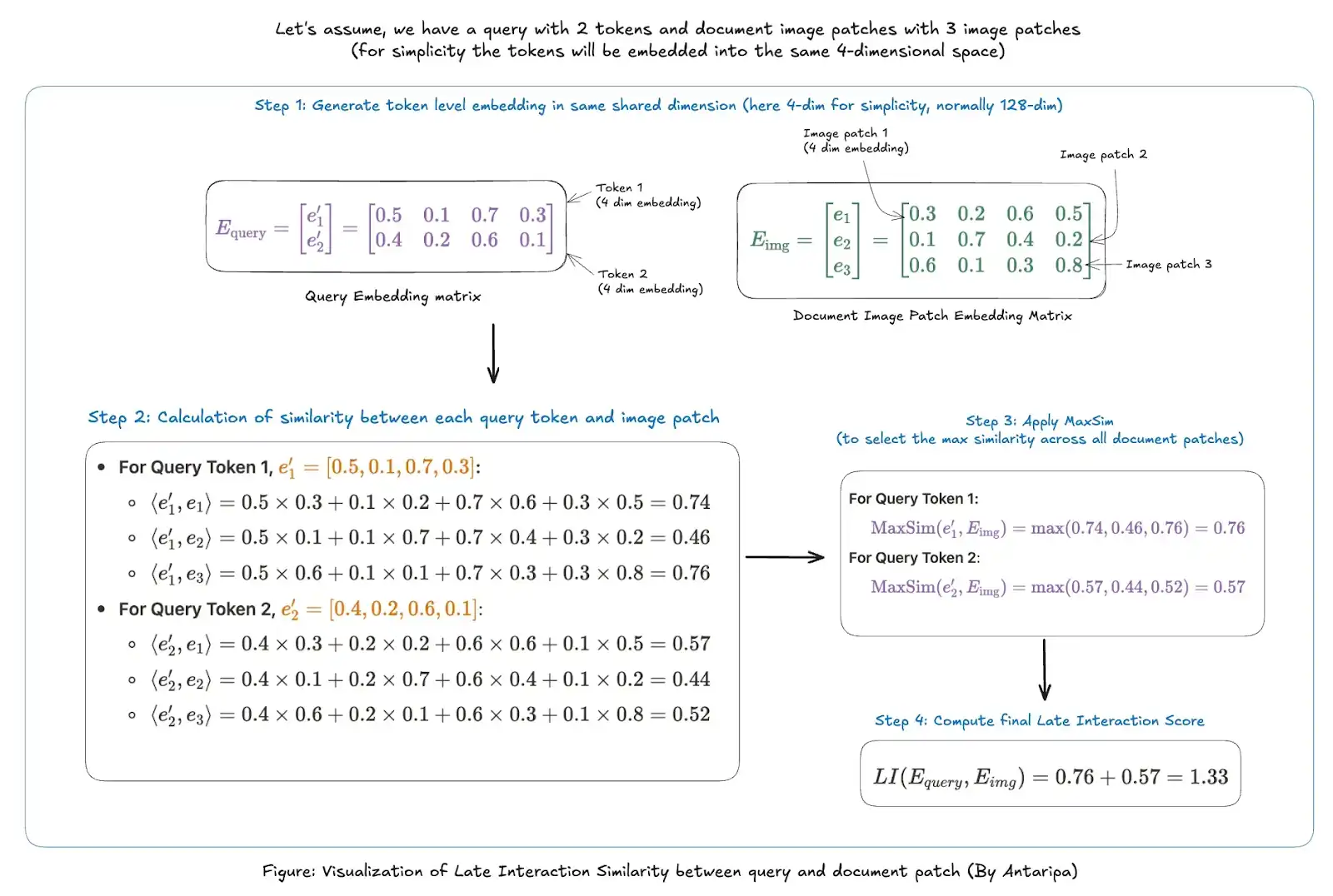
What’s Vespa?
Vespa is an open-source vector database and search platform that handles dense and sparse knowledge. It’s one in all two vector databases at the moment supporting multi-vector representations (the opposite one is QDrant). It allows knowledge retrieval, customized rating, and indexing methods.
On this hands-on information, we’ll pair ColQwen’s visible embedding energy with Vespa‘s search platform, to create a strong doc retrieval system. Vespa will function our vector db question engine. We’ll arrange a pipeline to deal with advanced paperwork like monetary studies, turning visually dense pages into searchable representations and enabling fast, correct retrieval.
Let’s dive in and get our arms soiled!
Colab pocket book: ColQwen_pdf_retrieval_and_interpretability.ipynb
NOTE: I’ve used each the A100 40GB GPU (colab professional) and the T4 GPU, which comes with free colab; each will work. Simply that it is possible for you to to embed only a few doc pages with the free model (OOM points will present up).
Step 1: Set up
# Set up important libraries
!pip set up transformers --upgrade
!pip set up colpali-engine --upgrade
!apt-get set up poppler-utils # for dealing with PDF pictures
!pip set up pdf2image pypdf
!pip set up qwen_vl_utils
!pip set up pyvespa vespacli # Vespa instrumentsWord: Be sure to have poppler-utils put in, because it’s wanted to transform PDF pages into pictures.
Step 2: Setting Up ColQwen for Picture Embedding
First, we import ColQwen, a mannequin from the ColPali household, which makes use of a Imaginative and prescient Language Mannequin (VLM) method to course of whole PDF pages as pictures.
from colpali_engine.fashions import ColQwen2, ColQwen2Processor
# Initialize ColQwen mannequin and processor
mannequin = ColQwen2.from_pretrained(
"vidore/colqwen2-v0.1",
torch_dtype=torch.bfloat16, # Use float16 if GPU doesn't assist bfloat16
device_map="auto",
)
processor = ColQwen2Processor.from_pretrained("vidore/colqwen2-v0.1")
mannequin = mannequin.eval()Step 3: Getting ready the PDFs
Right here, we’ll load and preprocess two pattern PDFs. You possibly can customise the URLs to make use of totally different paperwork. Each pdfs are finance paperwork, the second has a extra advanced construction (tables and knowledge are embedded within the picture). Each of those pdfs have 35 pages every.
pdf_lists = [
{"header": "Tesla finance",
"Url": "<https://ir.tesla.com/_flysystem/s3/sec/000162828024043432/tsla-20241023-gen.pdf>"},
{"header": "Understanding company finance",
"url": "<https://www.pwc.com/jm/en/research-publications/pdf/basic-understanding-of-a-companys-financials.pdf>"}
]Step 4: Downloading and Processing PDF Pages as Photographs
Create helper capabilities to obtain PDFs and convert every web page into pictures for embedding.
import requests
from io import BytesIO
from pdf2image import convert_from_path
# Utility to obtain a PDF file from a URL
def download_pdf(url):
response = requests.get(url)
if response.status_code == 200:
return BytesIO(response.content material)
else:
elevate Exception("Did not obtain PDF")
# Convert PDF pages to pictures
def get_pdf_images(pdf_url):
pdf_file = download_pdf(pdf_url)
pdf_file.search(0)
temp_file_path = "temp.pdf"
with open(temp_file_path, "wb") as f:
f.write(pdf_file.learn())
return convert_from_path(temp_file_path)download_pdf fetches the PDF from the URL, whereas get_pdf_images saves and converts every web page to a picture format appropriate with ColQwen.
Step 5: Encoding and Producing Embeddings for PDF Pages
Now, we’ll use ColQwen to create multi-vector embeddings for every web page picture. We batch-process pictures to generate embeddings effectively. Every PDF is now represented by embeddings for every web page picture, preserving each textual content and format.
from torch.utils.knowledge import DataLoader
from tqdm import tqdm
# Generate embeddings for pictures utilizing ColQwen
def generate_image_embeddings(pictures, mannequin, processor, batch_size=4): # modify batch_size in response to your machine's functionality
embeddings = []
dataloader = DataLoader(pictures, batch_size=batch_size, shuffle=False,
collate_fn=lambda x: processor.process_images(x))
for batch in tqdm(dataloader):
with torch.no_grad():
batch = {okay: v.to(mannequin.system) for okay, v in batch.objects()}
batch_embeddings = mannequin(**batch).to("cpu")
embeddings.lengthen(listing(batch_embeddings))
return embeddings
# Course of and retailer embeddings for every PDF within the listing
for pdf in pdf_lists:
header = pdf.get("header", "Unnamed Doc")
print(f"Processing {header}")
attempt:
pdf_page_images = get_pdf_images(pdf["url"])
pdf["images"] = pdf_page_images
pdf_embeddings = generate_image_embeddings(pdf_page_images, mannequin, processor)
pdf["embeddings"] = pdf_embeddings
besides Exception as e:
print(f"Error processing {header}: {e}")Output
Course of for Tesla finance pdf began100%|██████████| 9/9 [00:41<00:00, 4.61s/it]
Course of for Primary understanding of firm finance pdf began
100%|██████████| 9/9 [00:39<00:00, 4.40s/it]
Step 6: Encoding Photographs as Base64 and Structuring Knowledge for Vespa
The vespa_feed building resizes the picture in a presentable format, encodes pictures in base64 format, shops metadata, and binarizes the embeddings.
import base64
from PIL import Picture
# Encode pictures in base64
def encode_images_base64(pictures):
base64_images = []
for picture in pictures:
buffered = BytesIO()
picture.save(buffered, format="JPEG")
base64_images.append(base64.b64encode(buffered.getvalue()).decode('utf-8'))
return base64_images
def resize_image(pictures, max_height=800):
resized_images = []
for picture in pictures:
width, peak = picture.measurement
if peak > max_height:
ratio = max_height / peak
new_width = int(width * ratio)
new_height = int(peak * ratio)
resized_images.append(picture.resize((new_width, new_height)))
else:
resized_images.append(picture)
return resized_imagesWhy Base64?
The Base64 encoding is critical for storing picture knowledge in Vespa’s uncooked area format.
vespa_feed = []
for pdf in pdf_lists:
url = pdf["url"]
title = pdf["header"]
base64_images = encode_images_base64(resize_image(pdf["images"]))
for page_number, (embedding, picture, base64_img) in enumerate(zip(pdf["embeddings"], pdf["images"], base64_images)):
embedding_dict = dict()
for idx, patch_embedding in enumerate(embedding):
binary_vector = (
np.packbits(np.the place(patch_embedding > 0, 1, 0))
.astype(np.int8)
.tobytes()
.hex()
)
embedding_dict[idx] = binary_vector
web page = {
"id": hash(url + str(page_number)),
"url": url,
"title": title,
"page_number": page_number,
"picture": base64_img,
"embedding": embedding_dict,
}
vespa_feed.append(web page)This course of shops every doc’s metadata, embeddings, and pictures in a format appropriate with Vespa. The embeddings are binarized utilizing np.packbits, permitting for sooner and memory-efficient hamming distance calculations.
# Verifying the output of knowledge as soon as
print("Whole paperwork in vespa_feed: ", len(vespa_feed)) # complete numbers pages -> together with all pdfs
print(vespa_feed[0].keys())Output
Whole paperwork in vespa_feed: 70dict_keys(['id', 'url', 'title', 'page_number', 'image', 'embedding'])
Why Use Hamming Distance and Binarization?
By binarizing embeddings, the discount of the storage measurement is lowered by about 32x in comparison with utilizing float32 vectors. Hamming distance is then used to calculate the similarity between these binary vectors, offering an environment friendly, light-weight solution to carry out nearest-neighbour searches. Whereas binarization might barely scale back accuracy, it considerably boosts velocity, making it perfect for high-speed retrieval in massive doc units.
Not going in-detail for binary quantization, this useful resource covers brilliantly: Scaling ColPali to billions of PDFs with Vespa
Step 7: Making a Vespa Schema
To deal with doc embeddings and metadata, we outline a Vespa schema. Right here, we specify fields for storing picture embeddings, metadata (like title, web page quantity, url, and so on.), and binary vectors.
from vespa.package deal import ApplicationPackage, Schema, Doc, Subject, HNSW
colpali_schema = Schema(
title="finance_data_schema", # can title this something
doc=Doc(
fields=[
Field(name="id", type="string", indexing=["summary", "index"]),
Subject(title="url", sort="string", indexing=["summary", "index"]),
Subject(title="title", sort="string", indexing=["summary", "index"], index="enable-bm25"),
Subject(title="page_number", sort="int", indexing=["summary", "attribute"]),
Subject(title="picture", sort="uncooked", indexing=["summary"]),
Subject(title="embedding", sort="tensor<int8>(patch{}, v[16])", indexing=["attribute", "index"],
ann=HNSW(distance_metric="hamming"))
]
)
)The HNSW (Hierarchical Navigable Small World) index allows environment friendly similarity searches on vector embeddings.
Step 8: Defining Question Tensors for Retrieval
To course of advanced queries, we outline a number of question tensors that permit Vespa to make use of each binary and float representations. This setup allows environment friendly matching utilizing Hamming distance (for fast filtering with binary tensors) and MaxSim (for exact scoring with float tensors).
input_query_tensors = []
MAX_QUERY_TERMS = 64
for i in vary(MAX_QUERY_TERMS):
input_query_tensors.append((f"question(rq{i})", "tensor<int8>(v[16])"))
input_query_tensors.append(("question(qt)", "tensor<float>(querytoken{}, v[128])"))
input_query_tensors.append(("question(qtb)", "tensor<int8>(querytoken{}, v[16])"))- Binary Tensors (tensor<int8>(v[16])): Every question time period is represented as a binary tensor (e.g., question(rq{i})), used for quick preliminary filtering.
- Float Tensors (tensor<float>(querytoken{}, v[128])): Every question time period additionally has a float tensor (question(qt)), permitting for detailed similarity scoring throughout re-ranking.
This mixture of tensor sorts lets Vespa deal with related doc sections and ensures excessive precision in retrieval, even for visually advanced queries.
Step 9: Making a Multi-Section Rating Profile in Vespa
Subsequent, we outline a rating profile in Vespa that makes use of each Hamming distance (for binary similarity) and MaxSim (for float-based late interplay similarity) to rank paperwork. This profile allows a two-phase rating: a primary part for preliminary filtering utilizing binary similarity, and a second part for re-ranking with steady (float) similarity scores.
from vespa.package deal import RankProfile, Operate, FirstPhaseRanking, SecondPhaseRanking
colpali_retrieval_profile = RankProfile(
title="retrieval-and-rerank",
inputs=input_query_tensors,
capabilities=[
# First phase: Binary similarity using Hamming distance for fast filtering
Function(
name="max_sim_binary",
expression="""
sum(
reduce(
1/(1 + sum(
hamming(query(qtb), attribute(embedding)) ,v)
),
max,
patch
),
querytoken
)
""",
),
# Second phase: Float-based similarity using MaxSim for refined re-ranking
Function(
name="max_sim",
expression="""
sum(
reduce(
sum(
query(qt) * unpack_bits(attribute(embedding)) , v
),
max, patch
),
querytoken
)
""",
)
],
first_phase=FirstPhaseRanking(expression="max_sim_binary"), # Preliminary filtering with binary similarity
second_phase=SecondPhaseRanking(expression="max_sim", rerank_count=10), # Reranking prime 10 outcomes with float similarity
)
colpali_schema.add_rank_profile(colpali_retrieval_profile)MaxSim and Hamming Distance
When coping with huge datasets in vector databases like Vespa, we’d like a solution to discover related entries shortly. In ColQwen’s method, we use Hamming Distance and MaxSim capabilities to deal with this process effectively. Right here’s how every operate contributes:
- Hamming Distance: This can be a quick, preliminary filter that works with binary vectors (simplified variations of the embeddings). It compares vectors when it comes to bitwise similarity and calculates the variety of bits that differ between the question and every doc. Hamming Distance is computationally light-weight, making it a terrific alternative for fast filtering within the preliminary part. By decreasing the variety of candidates at this stage, we be sure that solely the most definitely matches transfer on to the subsequent spherical of rating. Right here, The max_sim_binary operate calculates binary similarity between question(qtb) and attribute(embedding) by counting bitwise matches.
- MaxSim: This operate is used for a extra exact comparability. MaxSim immediately compares embeddings in a steady vector house, capturing delicate variations that the binary filter would possibly overlook. The max_sim operate multiplies every question token (question(qt)) with corresponding doc patches and sums the utmost similarity scores throughout patches.
Binary Vector: A binary vector is a simplified illustration of knowledge, the place every aspect is both 0 or 1. This simplification makes sure calculations sooner, particularly when utilizing Hamming Distance, which relies on evaluating variations between bits.
Step 10: Deploying Vespa Software
With the configured utility, we are able to now deploy the Vespa schema and utility to Vespa Cloud.
To deploy the appliance to Vespa Cloud we have to create an account (free trial works) after which a tenant within the Vespa cloud.
For this step, tenant_name and app_name are required, which you’ll arrange in Vespa Cloud after creating your account. After the tenant is created, create an utility in Vespa Cloud and paste the title right here beneath. Since we’re not giving the important thing beneath, you might want to log in interactively from right here.
from vespa.deployment import VespaCloud
app_name = "colqwen_retrieval_app" # can title it something
tenant_name = "your-tenant-name" # Substitute together with your Vespa Cloud tenant title
vespa_application_package = ApplicationPackage(title=app_name, schema=[colpali_schema])
vespa_cloud = VespaCloud(tenant=tenant_name, utility=app_name, application_package=vespa_application_package)
app: Vespa = vespa_cloud.deploy()After deployment, be certain that to confirm the appliance’s standing within the Vespa Cloud Console.
Step 10: Feeding Knowledge to Vespa for Indexing
With our rating profile set, we are able to now feed the pre-processed knowledge to Vespa. Every doc (or web page) is embedded, binarized, and able to be listed for retrieval.
from vespa.io import VespaResponse
async with app.asyncio(connections=1, timeout=180) as session:
for web page in vespa_feed:
response: VespaResponse = await session.feed_data_point(
data_id=web page["id"], fields=web page, schema="finance_data_schema"
)
if not response.is_successful():
print(response.json())Output
100%|██████████| 70/70 [00:51<00:00, 1.36it/s]
A complete of 70 pages (from each PDFs) are inserted into Vespa. Every doc (web page) is uploaded to Vespa together with its ID, URL, title, web page quantity, base64 picture, and binary embeddings for retrieval. This setup permits for each metadata-based filtering (like by title) and embedding-based similarity searches.
Step 11: Querying Vespa and Displaying Outcomes
The helper operate shows outcomes pictures as soon as queries are comprised of Vespa.
from IPython.show import show, HTML
# Show question outcomes pictures
def display_query_results(question, response, hits=5):
query_time = response.json.get("timing", {}).get("searchtime", -1)
query_time = spherical(query_time, 2)
rely = response.json.get("root", {}).get("fields", {}).get("totalCount", 0)
html_content = f"<h3>Question textual content: '{question}', question time {query_time}s, rely={rely}, prime outcomes:</h3>"
for i, hit in enumerate(response.hits[:hits]):
title = hit["fields"]["title"]
url = hit["fields"]["url"]
web page = hit["fields"]["page_number"]
picture = hit["fields"]["image"]
rating = hit["relevance"]
html_content += f"<h4>PDF End result {i + 1}</h4>"
html_content += f'<p><robust>Title:</robust> <a href="https://www.analyticsvidhya.com/weblog/2024/10/multimodal-retrieval-with-colqwen-vespa/{url}">{title}</a>, web page {web page+1} with rating {rating:.2f}</p>'
html_content += (
f'<img src="knowledge:picture/png;base64,{picture}" model="max-width:100%;">'
)
show(HTML(html_content))Now, we are able to question Vespa utilizing ColQwen embeddings and visualize the outcomes. The display_query_results operate codecs and shows the highest outcomes, together with picture previews and relevance scores for every web page.
queries = ["balance at 1 July 2017 for equity holders"] # you possibly can go a number of queries right here
dataloader = DataLoader(
queries,
batch_size=1,
shuffle=False,
collate_fn=lambda x: processor.process_queries(x),
)
qs = []
for batch_query in dataloader:
with torch.no_grad():
batch_query = {okay: v.to(mannequin.system) for okay, v in batch_query.objects()}
embeddings_query = mannequin(**batch_query)
qs.lengthen(listing(torch.unbind(embeddings_query.to("cpu"))))Generated the embeddings of the question from the identical ColQwen mannequin.
Subsequent, we carry out the ultimate search on the listed paperwork, retrieving pages primarily based on the question tokens and their embeddings, and the display_query_results operate reveals every web page’s title, URL, web page quantity, relevance rating, and a preview picture.
target_hits_per_query_tensor = (
5 # this can be a hyperparameter that may be tuned for velocity versus accuracy
)
async with app.asyncio(connections=1, timeout=180) as session:
for idx, question in enumerate(queries):
float_query_embedding = {okay: v.tolist() for okay, v in enumerate(qs[idx])}
binary_query_embeddings = dict()
for okay, v in float_query_embedding.objects():
binary_query_embeddings[k] = (
np.packbits(np.the place(np.array(v) > 0, 1, 0)).astype(np.int8).tolist()
)
# The blended tensors utilized in MaxSim calculations
# We use each binary and float representations
query_tensors = {
"enter.question(qtb)": binary_query_embeddings,
"enter.question(qt)": float_query_embedding,
}
# The question tensors used within the nearest neighbor calculations
for i in vary(0, len(binary_query_embeddings)):
query_tensors[f"input.query(rq{i})"] = binary_query_embeddings[i]
nn = []
for i in vary(0, len(binary_query_embeddings)):
nn.append(
f"({{targetHits:{target_hits_per_query_tensor}}}nearestNeighbor(embedding,rq{i}))"
)
# We use a OR operator to mix the closest neighbor operator
nn = " OR ".be part of(nn)
response: VespaQueryResponse = await session.question(
yql=f"choose title, url, picture, page_number from pdf_page the place {nn}",
rating="retrieval-and-rerank",
timeout=120,
hits=3,
physique={**query_tensors, "presentation.timing": True},
)
assert response.is_successful()
display_query_results(question, response)Output
End result 1 for question: “steadiness at 1 July 2017 for fairness holders”, is picture 11
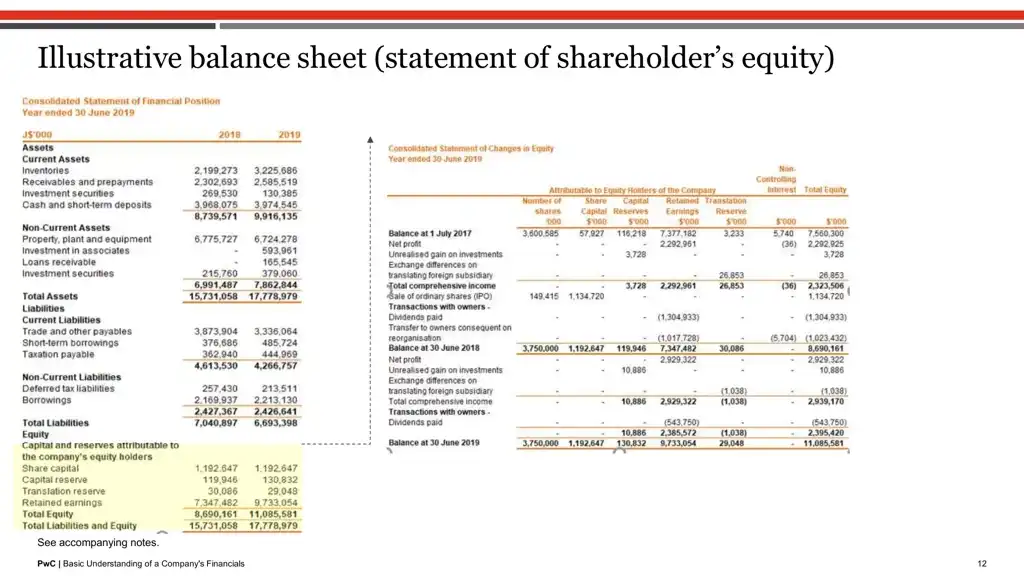
End result 2 for question: “steadiness at 1 July 2017 for fairness holders”, is picture 5
Right here, exhibiting the highest two retrieved outputs above. As you possibly can see, the highest picture precisely has the phrases “steadiness”, “1 July 2017”, “fairness”.
Now let’s extract the identical pdf web page from pdfreader to examine if the textual content was current in textual content format or was embedded in a picture. This step is attention-grabbing as a result of it reveals the restrictions of an ordinary PDF textual content extractor when coping with advanced paperwork the place textual content is primarily embedded as pictures. (Ps: in case you open this PDF, you’ll discover that many of the textual content isn’t selectable.)
By extracting textual content from the second PDF, we illustrate that the PDF extractor struggles to retrieve significant textual content since virtually every part is embedded inside pictures.
url = "<https://www.pwc.com/jm/en/research-publications/pdf/basic-understanding-of-a-companys-financials.pdf>"
pdf_file = download_pdf(pdf["url"])
pdf_file.search(0) # Reset file pointer for picture conversion
# will get textual content of every web page from the PDF
temp_file_path = "take a look at.pdf"
with open(temp_file_path, "wb") as f:
f.write(pdf_file.learn())
reader = PdfReader(temp_file_path)
page_texts = []
for page_number in vary(len(reader.pages)):
web page = reader.pages[page_number]
textual content = web page.extract_text()
page_texts.append(textual content)
print(page_texts[11]) # printing the textual content from eleventh index web page (from 2nd pdf)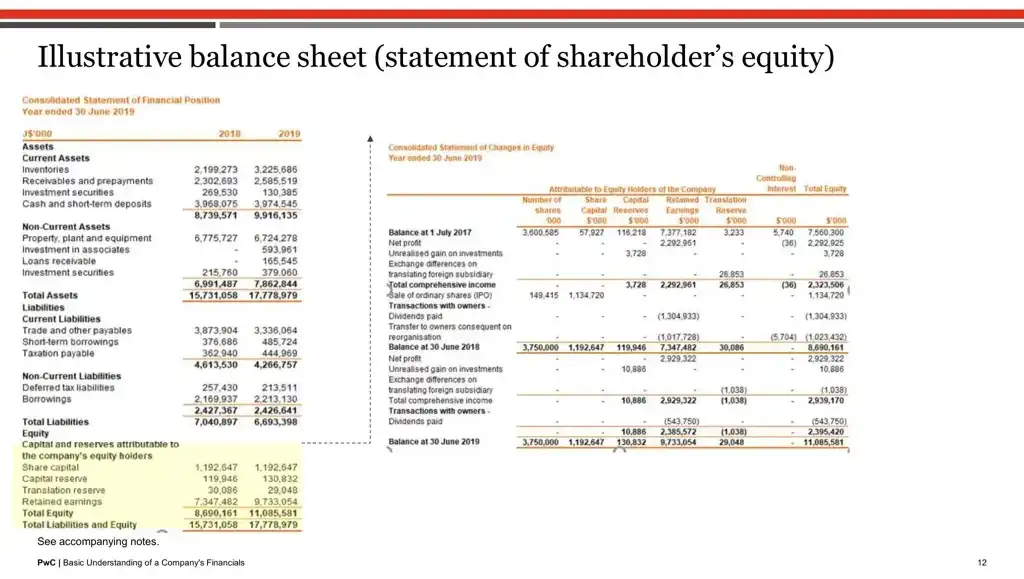
Output
"12 PwC | Primary Understanding of a Firm's FinancialsIllustrative steadiness sheet (assertion of shareholder’s fairness)
See accompanying notes."
As we are able to see hardly any textual content could possibly be extracted due to the embedded nature.
Step 12: Interpretability with ColQwen – Visualizing Related Patches
A significant benefit of ColQwen lies in its interpretability. Past merely returning outcomes, ColQwen offers insights into why sure pages or sections of paperwork had been chosen primarily based on the question. This transparency is achieved by similarity maps, which visually spotlight probably the most related areas of every retrieved doc.
question = "steadiness at 1 July 2017 for fairness holders"
idx = 11 # prime retrieved index
top_image = pdf_lists[1]["images"][idx]
pdf_embeddings = pdf_lists[1]["embeddings"]
# Get the variety of picture patches
n_patches = processor.get_n_patches(
image_size=top_image.measurement,
patch_size=mannequin.patch_size,
spatial_merge_size=mannequin.spatial_merge_size,
)
# Get the tensor masks to filter out the embeddings that aren't associated to the picture
image_mask = processor.get_image_mask(processor.process_images([top_image]))
batch_queries = processor.process_queries([query]).to(mannequin.system)
# Generate the similarity maps
batched_similarity_maps = get_similarity_maps_from_embeddings(
image_embeddings=pdf_embeddings[idx].unsqueeze(0).to("cuda"),
query_embeddings=mannequin(**batch_queries),
n_patches=n_patches,
image_mask=image_mask,
)
query_content = processor.decode(batch_queries.input_ids[0]).substitute(processor.tokenizer.pad_token, "")
query_content = query_content.substitute(processor.query_augmentation_token, "").strip()
query_tokens = processor.tokenizer.tokenize(query_content)
# Get the similarity map for our (solely) enter picture
similarity_maps = batched_similarity_maps[0] # (query_length, n_patches_x, n_patches_y)Above, we’re making a “similarity map” to interpret how the mannequin connects particular elements of a question (like “steadiness at 1 July 2017 for fairness holders”) to areas of a picture extracted from a PDF. This similarity map helps visually signify which elements of the picture are related to every phrase within the question, making the mannequin’s choice course of interpretable.
print(query_tokens) # examine the tokens of the question after tokenization course ofOutput
['Query', ':', 'Ġbalance', 'Ġat', 'Ġ', '1', 'ĠJuly', 'Ġ', '2', '0', '1', '7', 'Ġfor', 'Ġequity', 'Ġholders']
We’ll visualize the heatmap for 2 tokens within the question “steadiness” and “July”:
idx = 11 # prime retrieved web page from vespa
top_image = pdf_lists[1]["images"][idx]
token_idx = 2 # visualizing for 2nd index token from the query_tokens which is 'steadiness'
fig, ax = plot_similarity_map(
picture=top_image,
similarity_map=similarity_maps[token_idx],
figsize=(8, 8),
show_colorbar=False,
)
max_sim_score = similarity_maps[token_idx, :, :].max().merchandise()
ax.set_title(f"Token #{token_idx}: `{query_tokens[token_idx].substitute('Ġ', '_')}`. MaxSim rating: {max_sim_score:.2f}", fontsize=14)
del query_content, query_tokens, batch_queries, batched_similarity_maps, similarity_maps, image_mask, n_patches, top_image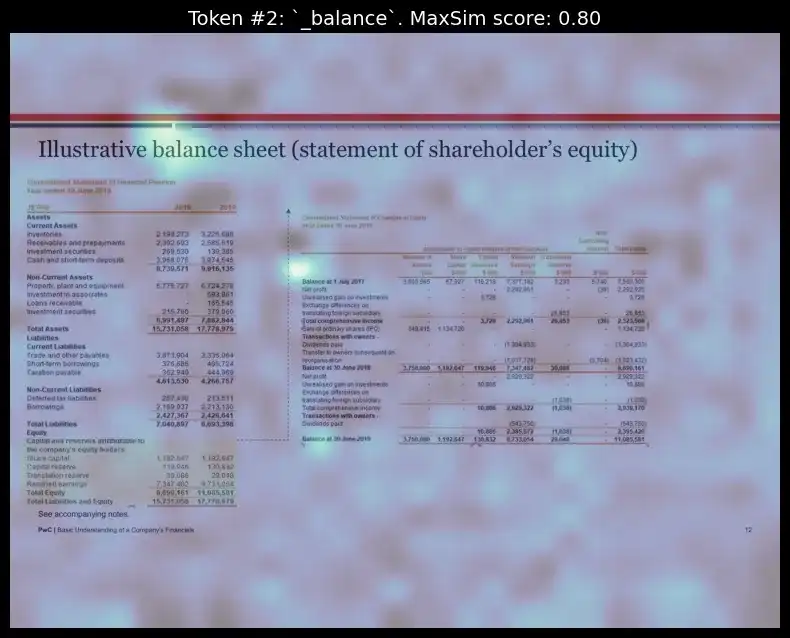
Visualizing the heatmap for the token ‘July’:
idx = 11
top_image = pdf_lists[1]["images"][idx]
token_idx = 6 # visualizing for 2nd index token from the query_tokens which is 'July'
fig, ax = plot_similarity_map(
picture=top_image,
similarity_map=similarity_maps[token_idx],
figsize=(8, 8),
show_colorbar=False,
)
max_sim_score = similarity_maps[token_idx, :, :].max().merchandise()
ax.set_title(f"Token #{token_idx}: `{query_tokens[token_idx].substitute('Ġ', '_')}`. MaxSim rating: {max_sim_score:.2f}", fontsize=14)
del query_content, query_tokens, batch_queries, batched_similarity_maps, similarity_maps, image_mask, n_patches, top_image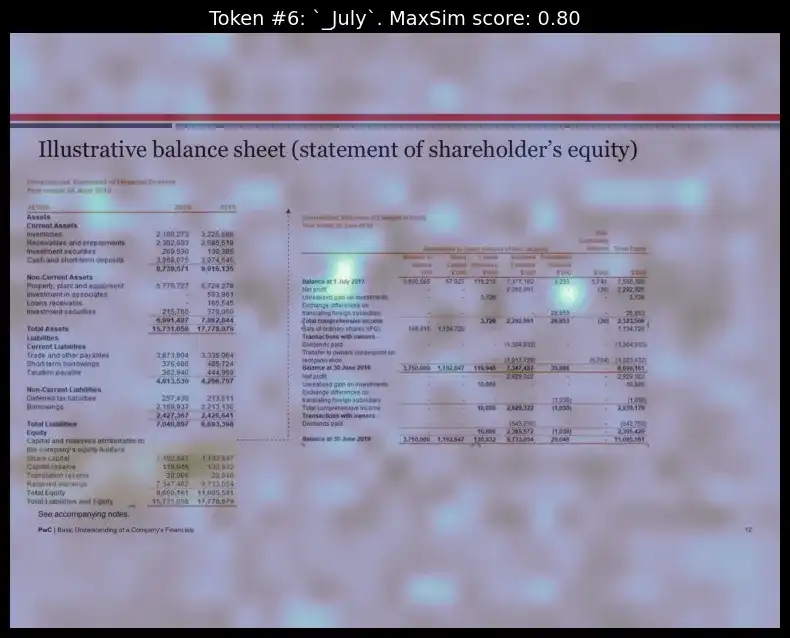
We will see how, for every of the respective tokens, the mannequin may correctly determine the format place these phrases had been current and highlighted them.
The interpretability layer reveals which elements of the doc matched the question, permitting customers to know the retrieval logic higher. This characteristic enhances transparency by revealing why sure pages had been chosen.
Conclusion
On this weblog, we explored how ColQwen’s superior Imaginative and prescient Language Mannequin, mixed with Vespa’s highly effective multi-vector search, is reshaping the way in which we retrieve visually dense doc knowledge. By immediately embedding whole pages as pictures and leveraging multi-vector embeddings, this method avoids the pitfalls of conventional text-only extraction, making it doable to retrieve info that isn’t solely correct but additionally contextually conscious.
ColQwen’s interpretability and explainability carry much-needed transparency to industries like finance, regulation, and healthcare, the place context is every part.
Developments in multimodal retrieval have been taking over this 12 months and this highly effective mixture of ColQwen + Vespa is only one such instance of how we are able to make doc search as intuitive and dependable. Hope you preferred the weblog, let me know you probably have any ideas.
If you’re on the lookout for a Generative AI course on-line then discover: GenAI Pinnacle Program
Continuously Requested Questions
Ans. ColQwen / ColPali immediately embeds whole pages as pictures slightly than counting on textual content extraction by way of OCR. This method retains the visible format and context of paperwork, making it perfect for advanced paperwork like monetary studies and analysis papers the place format is important.
Ans. As soon as ColQwen / ColPali has the photographs of the doc, it divides the web page into small, uniform items known as patches (for eg, 16×16 pixels). Every patch is then handed by a Imaginative and prescient Transformer (ViT), which converts them into distinctive embeddings.
Ans. The Late Interplay mechanism in ColPali is designed to carry out token-level similarity matching between the textual content question and doc picture patches. Not like conventional retrieval fashions that scale back every part right into a single embedding vector for comparability, Late Interplay operates on particular person token embeddings, preserving granular particulars and enhancing accuracy in retrieval duties.
The important thing thought is that for every question token, ColPali finds probably the most related picture patch within the doc. The mannequin then aggregates these relevance scores to compute the general similarity between the question and the doc.
Ans. Sure, ColQwen is flexible and might deal with varied doc sorts, particularly these with wealthy visible buildings. Nevertheless, it shines finest in circumstances the place each textual content and visible parts (like tables and pictures) present essential context. When it comes to value, it is going to be costlier because it saves the embeddings in a multivector format.