Introduction
You know the way we’re all the time listening to about “various” datasets in machine studying? Properly, it turns on the market’s been an issue with that. However don’t fear – a superb group of researchers has simply dropped a game-changing paper that’s acquired the entire ML neighborhood buzzing. Within the paper that lately gained the ICML 2024 Greatest Paper Award, researchers Dora Zhao, Jerone T. A. Andrews, Orestis Papakyriakopoulos, and Alice Xiang deal with a crucial concern in machine studying (ML) – the customarily obscure and unsubstantiated claims of “range” in datasets. Their work, titled “Measure Dataset Variety, Don’t Simply Declare It,” proposes a structured method to conceptualizing, operationalizing, and evaluating range in ML datasets utilizing rules from measurement idea.

Now, I do know what you’re pondering. “One other paper about dataset range? Haven’t we heard this earlier than?” However belief me, this one’s totally different. These researchers have taken a tough take a look at how we use phrases like “range,” “high quality,” and “bias” with out actually backing them up. We’ve been enjoying quick and unfastened with these ideas, and so they’re calling us out on it.
However right here’s one of the best half—they’re not simply declaring the issue. They’ve developed a strong framework to assist us measure and validate range claims. They’re handing us a toolbox to repair this messy state of affairs.
So, buckle up as a result of I’m about to take you on a deep dive into this groundbreaking analysis. We are going to discover how we will transfer past claiming range to measuring it. Belief me, by the top of this, you’ll by no means take a look at an ML dataset the identical method once more!
The Downside with Variety Claims
The authors spotlight a pervasive concern within the Machine studying neighborhood: dataset curators steadily make use of phrases like “range,” “bias,” and “high quality” with out clear definitions or validation strategies. This lack of precision hampers reproducibility and perpetuates the misperception that datasets are impartial entities somewhat than value-laden artifacts formed by their creators’ views and societal contexts.
A Framework for Measuring Variety
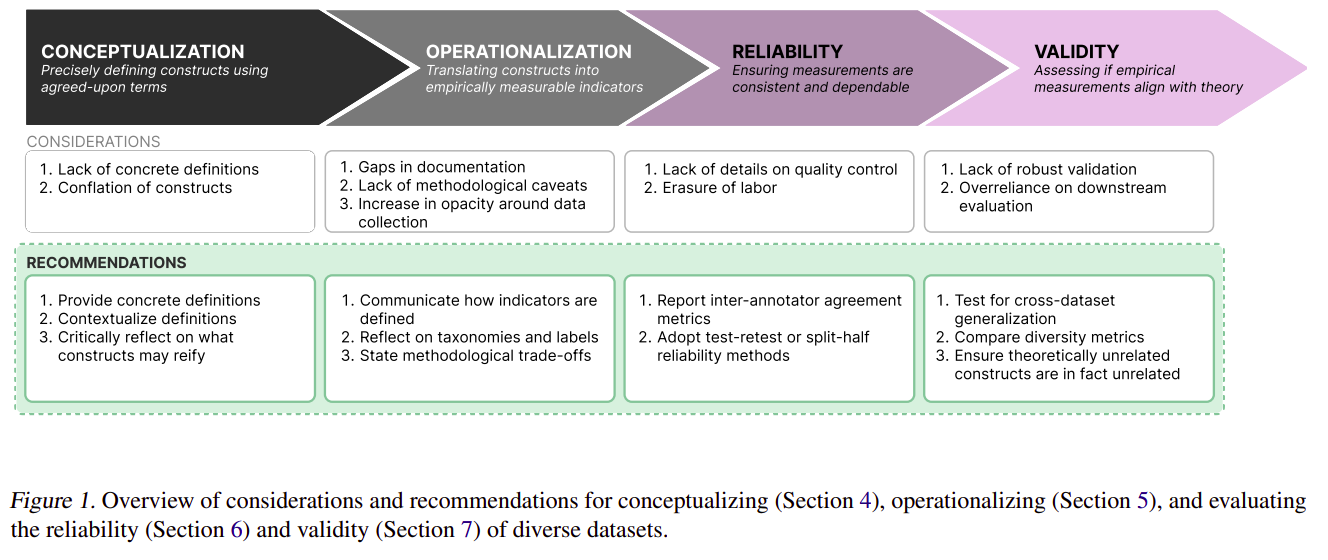
Drawing from social sciences, notably measurement idea, the researchers current a framework for reworking summary notions of range into measurable constructs. This method entails three key steps:
- Conceptualization: Clearly defining what “range” means within the context of a selected dataset.
- Operationalization: Growing concrete strategies to measure the outlined points of range.
- Analysis: Assessing the reliability and validity of the variety measurements.
In abstract, this place paper advocates for clearer definitions and stronger validation strategies in creating various datasets, proposing measurement idea as a scaffolding framework for this course of.
Key Findings and Suggestions
By means of an evaluation of 135 picture and textual content datasets, the authors uncovered a number of essential insights:
- Lack of Clear Definitions: Solely 52.9% of datasets explicitly justified the necessity for various knowledge. The paper emphasizes the significance of offering concrete, contextualized definitions of range.
- Documentation Gaps: Many papers introducing datasets fail to supply detailed details about assortment methods or methodological selections. The authors advocate for elevated transparency in dataset documentation.
- Reliability Considerations: Solely 56.3% of datasets lined high quality management processes. The paper recommends utilizing inter-annotator settlement and test-retest reliability to evaluate dataset consistency.
- Validity Challenges: Variety claims typically lack sturdy validation. The authors recommend utilizing strategies from assemble validity, reminiscent of convergent and discriminant validity, to judge whether or not datasets actually seize the supposed range of constructs.
Sensible Utility: The Phase Something Dataset
As an example their framework, the paper features a case examine of the Phase Something dataset (SA-1B). Whereas praising sure points of SA-1B’s method to range, the authors additionally establish areas for enchancment, reminiscent of enhancing transparency across the knowledge assortment course of and offering stronger validation for geographic range claims.
Broader Implications
This analysis has important implications for the ML neighborhood:
- Difficult “Scale Considering”: The paper argues in opposition to the notion that range routinely emerges with bigger datasets, emphasizing the necessity for intentional curation.
- Documentation Burden: Whereas advocating for elevated transparency, the authors acknowledge the substantial effort required and name for systemic modifications in how knowledge work is valued in ML analysis.
- Temporal Concerns: The paper highlights the necessity to account for a way range constructs could change over time, affecting dataset relevance and interpretation.
You’ll be able to learn the paper right here: Place: Measure DatasetOkay Variety, Don’t Simply Declare It
Conclusion
This ICML 2024 Greatest Paper provides a path towards extra rigorous, clear, and reproducible analysis by making use of measurement idea rules to ML dataset creation. As the sector grapples with problems with bias and illustration, the framework offered right here gives helpful instruments for guaranteeing that claims of range in ML datasets should not simply rhetoric however measurable and significant contributions to growing truthful and sturdy AI methods.
This groundbreaking work serves as a name to motion for the ML neighborhood to raise the requirements of dataset curation and documentation, in the end resulting in extra dependable and equitable machine studying fashions.
I’ve acquired to confess, after I first noticed the authors’ suggestions for documenting and validating datasets, part of me thought, “Ugh, that feels like loads of work.” And yeah, it’s. However you recognize what? It’s work that must be finished. We are able to’t preserve constructing AI methods on shaky foundations and simply hope for one of the best. However right here’s what acquired me fired up: this paper isn’t nearly bettering our datasets. It’s about making our total discipline extra rigorous, clear, and reliable. In a world the place AI is turning into more and more influential, that’s enormous.
So, what do you suppose? Are you able to roll up your sleeves and begin measuring dataset range? Let’s chat within the feedback – I’d love to listen to your ideas on this game-changing analysis!
You’ll be able to learn different ICML 2024 Greatest Paper‘s right here: ICML 2024 High Papers: What’s New in Machine Studying.
Steadily Requested Questions
Ans. Measuring dataset range is essential as a result of it ensures that the datasets used to coach machine studying fashions characterize varied demographics and situations. This helps cut back biases, enhance fashions’ generalizability, and promote equity and fairness in AI methods.
Ans. Various datasets can enhance the efficiency of ML fashions by exposing them to a variety of situations and lowering overfitting to any specific group or state of affairs. This results in extra sturdy and correct fashions that carry out effectively throughout totally different populations and circumstances.
Ans. Widespread challenges embrace defining what constitutes range, operationalizing these definitions into measurable constructs, and validating the variety claims. Moreover, guaranteeing transparency and reproducibility in documenting the variety of datasets could be labor-intensive and sophisticated.
Ans. Sensible steps embrace:
a. Clearly defining range objectives and standards particular to the venture.
b. Accumulating knowledge from varied sources to cowl totally different demographics and situations.
c. Utilizing standardized strategies to measure and doc range in datasets.
d. Constantly consider and replace datasets to take care of range over time.
e.Implementing sturdy validation strategies to make sure the datasets genuinely replicate the supposed range.