You’ve seemingly heard {that a} image is value a thousand phrases, however can a big language mannequin (LLM) get the image if it’s by no means seen photographs earlier than?
Because it seems, language fashions which are skilled purely on textual content have a stable understanding of the visible world. They’ll write image-rendering code to generate complicated scenes with intriguing objects and compositions — and even when that information shouldn’t be used correctly, LLMs can refine their photographs. Researchers from MIT’s Laptop Science and Synthetic Intelligence Laboratory (CSAIL) noticed this when prompting language fashions to self-correct their code for various photographs, the place the techniques improved on their easy clipart drawings with every question.
The visible information of those language fashions is gained from how ideas like shapes and colours are described throughout the web, whether or not in language or code. When given a path like “draw a parrot within the jungle,” customers jog the LLM to think about what it’s learn in descriptions earlier than. To evaluate how a lot visible information LLMs have, the CSAIL workforce constructed a “imaginative and prescient checkup” for LLMs: utilizing their “Visible Aptitude Dataset,” they examined the fashions’ talents to attract, acknowledge, and self-correct these ideas. Gathering every remaining draft of those illustrations, the researchers skilled a pc imaginative and prescient system that identifies the content material of actual photographs.
“We primarily prepare a imaginative and prescient system with out straight utilizing any visible information,” says Tamar Rott Shaham, co-lead creator of the examine and an MIT electrical engineering and pc science (EECS) postdoc at CSAIL. “Our workforce queried language fashions to put in writing image-rendering codes to generate information for us after which skilled the imaginative and prescient system to guage pure photographs. We had been impressed by the query of how visible ideas are represented via different mediums, like textual content. To specific their visible information, LLMs can use code as a standard floor between textual content and imaginative and prescient.”
To construct this dataset, the researchers first queried the fashions to generate code for various shapes, objects, and scenes. Then, they compiled that code to render easy digital illustrations, like a row of bicycles, exhibiting that LLMs perceive spatial relations properly sufficient to attract the two-wheelers in a horizontal row. As one other instance, the mannequin generated a car-shaped cake, combining two random ideas. The language mannequin additionally produced a glowing mild bulb, indicating its means to create visible results.
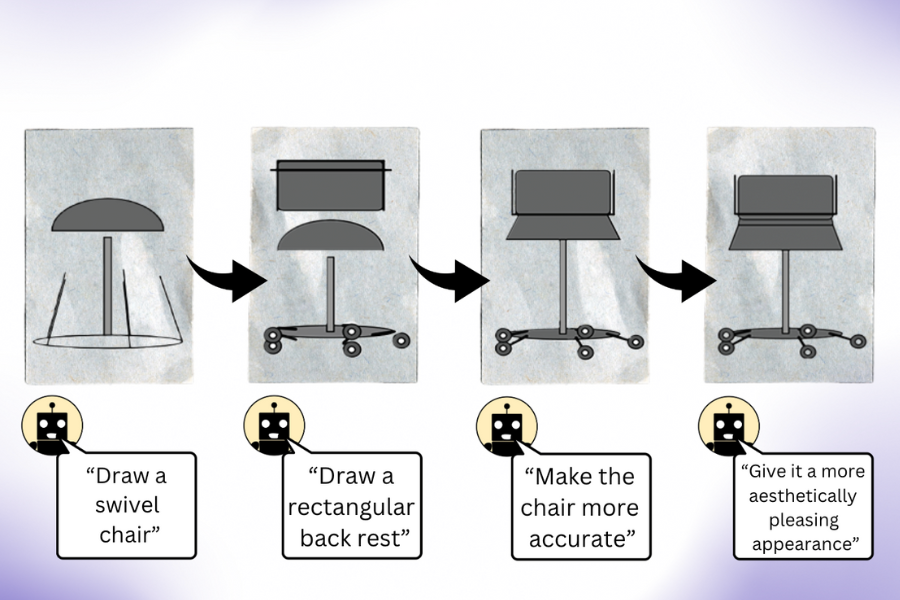
“Our work exhibits that if you question an LLM (with out multimodal pre-training) to create a picture, it is aware of rather more than it appears,” says co-lead creator, EECS PhD scholar, and CSAIL member Pratyusha Sharma. “Let’s say you requested it to attract a chair. The mannequin is aware of different issues about this piece of furnishings that it could not have instantly rendered, so customers can question the mannequin to enhance the visible it produces with every iteration. Surprisingly, the mannequin can iteratively enrich the drawing by bettering the rendering code to a big extent.”
The researchers gathered these illustrations, which had been then used to coach a pc imaginative and prescient system that may acknowledge objects inside actual photographs (regardless of by no means having seen one earlier than). With this artificial, text-generated information as its solely reference level, the system outperforms different procedurally generated picture datasets that had been skilled with genuine photographs.
The CSAIL workforce believes that combining the hidden visible information of LLMs with the creative capabilities of different AI instruments like diffusion fashions is also useful. Programs like Midjourney generally lack the know-how to persistently tweak the finer particulars in a picture, making it tough for them to deal with requests like lowering what number of automobiles are pictured, or inserting an object behind one other. If an LLM sketched out the requested change for the diffusion mannequin beforehand, the ensuing edit could possibly be extra passable.
The irony, as Rott Shaham and Sharma acknowledge, is that LLMs generally fail to acknowledge the identical ideas that they’ll draw. This grew to become clear when the fashions incorrectly recognized human re-creations of photographs inside the dataset. Such various representations of the visible world seemingly triggered the language fashions’ misconceptions.
Whereas the fashions struggled to understand these summary depictions, they demonstrated the creativity to attract the identical ideas in a different way every time. When the researchers queried LLMs to attract ideas like strawberries and arcades a number of occasions, they produced photos from various angles with various shapes and colours, hinting that the fashions might need precise psychological imagery of visible ideas (quite than reciting examples they noticed earlier than).
The CSAIL workforce believes this process could possibly be a baseline for evaluating how properly a generative AI mannequin can prepare a pc imaginative and prescient system. Moreover, the researchers look to increase the duties they problem language fashions on. As for his or her current examine, the MIT group notes that they don’t have entry to the coaching set of the LLMs they used, making it difficult to additional examine the origin of their visible information. Sooner or later, they intend to discover coaching an excellent higher imaginative and prescient mannequin by letting the LLM work straight with it.
Sharma and Rott Shaham are joined on the paper by former CSAIL affiliate Stephanie Fu ’22, MNG ’23 and EECS PhD college students Manel Baradad, Adrián Rodríguez-Muñoz ’22, and Shivam Duggal, who’re all CSAIL associates; in addition to MIT Affiliate Professor Phillip Isola and Professor Antonio Torralba. Their work was supported, partially, by a grant from the MIT-IBM Watson AI Lab, a LaCaixa Fellowship, the Zuckerman STEM Management Program, and the Viterbi Fellowship. They current their paper this week on the IEEE/CVF Laptop Imaginative and prescient and Sample Recognition Convention.