With the development of Deep Studying (DL), the invention of Visible Query Answering (VQA) has turn into potential. VQA has just lately turn into fashionable among the many pc imaginative and prescient analysis neighborhood as researchers are heading in direction of multi-modal issues. VQA is a difficult but promising multidisciplinary Synthetic Intelligence (AI) activity that allows a number of purposes.
On this weblog we’ll cowl:
- Overview of Visible Query Answering
- The basic rules of VQA
- Engaged on a VQA system
- VQA datasets
- Purposes of VQA throughout numerous industries
- Current developments and future challenges
What’s Visible Query Answering (VQA)?
The best means of defining a VQA system is a system able to answering questions associated to a picture. It takes a picture and a text-based query as inputs and generates the reply as output. The character of the issue defines the character of the enter and output of a VQA mannequin.
Inputs could embrace static photos, movies with audio, and even infographics. Questions might be introduced throughout the visible or requested individually relating to the visible enter. It may well reply multiple-choice questions, YES/NO (binary questions), or any open-ended questions concerning the supplied enter picture. It permits a pc program to grasp and reply to visible and textual enter in a human-like method.

- Are there any telephones close to the desk?
- Guess the variety of burgers on the desk.
- Guess the colour of the desk?
- Learn the textual content within the picture if any.
A visible query answering mannequin would be capable to reply the above questions concerning the picture.
Because of its complicated nature and being a multimodal activity (methods that may interpret and comprehend information from numerous modalities, together with textual content, photos, and typically audio), VQA is taken into account AI-complete or AI-hard (probably the most troublesome downside within the AI area) as it’s equal to creating computer systems as clever as people.
Rules Behind VQA
Visible query answering naturally works with picture and textual content modalities.
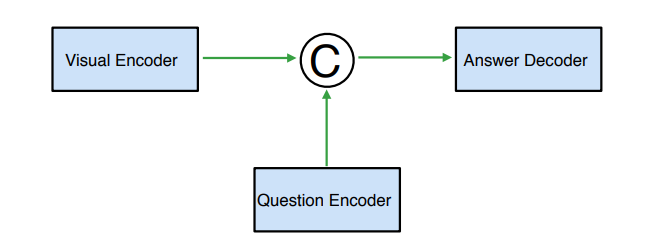
A VQA mannequin has the next parts:
- Laptop Imaginative and prescient (CV)
CV is used for picture processing and extraction of the related options. For picture classification and object recognition in a picture, CNN (Convolution Neural Networks) are utilized. OpenCV and Viso Suite are appropriate platforms for this strategy. Such strategies function by capturing the native and international visible options from a picture. - Pure Language Processing (NLP)
NLP works parallel with CV in any VQA mannequin. NLP processes the information with pure language textual content or voice. Lengthy Quick-Time period Reminiscence (LSTM) networks or Bag-Of-Phrases (BOW) are largely used to extract query options. These strategies perceive the sequential nature of the query’s language and convert it to numerical information numerical information for NLP. - Combining CV And NLP
That is the conjugation half in a VQA mannequin. The character of the ultimate reply is derived from this integration of visible and textual options. Completely different architectures, equivalent to CNNs and Recurrent Neural Networks (RNNs) mixed, Consideration Mechanisms, and even Multilayer Perceptrons (MLPs) are used on this strategy.
How Does a VQA System Work?
A Visible Query Answering mannequin can deal with a number of picture inputs. It may well take visible enter as photos, movies, GIFs, units of photos, diagrams, slides, and 360◦ photos. From a broader perspective, a visible query reply system undergoes the next phases:
- Picture Function Extraction: Transformation of photos into readable characteristic illustration to course of additional.
- Query Function Extraction: Encoding of the pure language inquiries to extract related entities and ideas.
- Function Conjugation: Strategies of mixing encoded picture and query options.
- Reply Era: Understanding the built-in options to generate the ultimate reply.
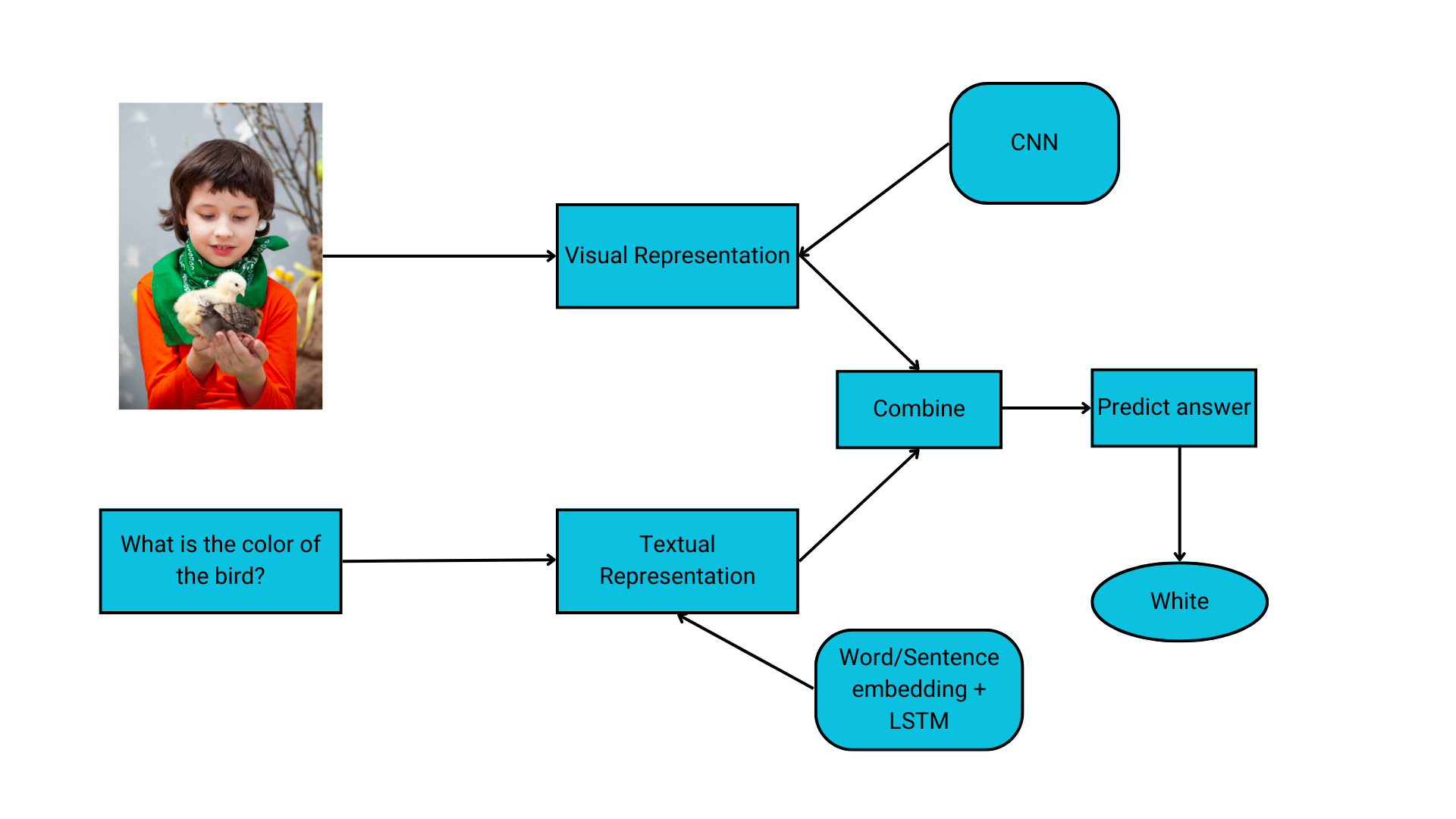
Picture Function Extraction
Nearly all of VQA fashions use CNN to course of visible imagery. Deep convolutional neural networks obtain photos as enter and use them to coach a classifier. CNN’s fundamental goal for VQA is picture featurization. It makes use of a linear mathematical operation of “convolution” and never easy matrix multiplication.
Relying on the complexity of the enter visible, the variety of layers could vary from tons of to 1000’s. Every layer builds on the outputs of those earlier than it to determine complicated patterns.
A number of Visible Query Answering papers revealed that a lot of the fashions used VGGet earlier than ResNets (8x deeper than VGG nets) got here in 2017 for picture characteristic extraction.
Query Function Extraction
The literature on VQA means that Lengthy Quick-Time period Reminiscence (LSTMs) are generally used for query featurization, a sort of Recurrent Neural Community (RNN). Because the title depicts, RNNs have a looping or recurrent workflow; they work by passing sequential information that they obtain to the hidden layers one step at a time.
The short-term reminiscence element on this neural community makes use of a hidden layer to recollect and use previous inputs for future predictions. The following sequence is then predicted primarily based on the present enter and saved reminiscence.
RNNs have issues with exploding and vanishing gradients whereas coaching a deep neural community. LSTMs overcome this. A number of different strategies equivalent to count-based and frequency-based strategies like rely vectorization and TF-IDF (Time period Frequency-Inverse Doc Frequency) are additionally accessible.
For pure language processing, prediction-based strategies equivalent to a steady bag of phrases and skip grams are used as nicely. Word2Vec pre-trained algorithms are additionally relevant.
A skip-gram mannequin predicts the phrases round a given phrase by maximizing the probability of accurately guessing context phrases primarily based on a goal phrase. So, for a sequence of phrases w1, w2, … wT, the target of the mannequin is to precisely predict close by phrases.
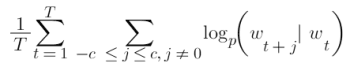
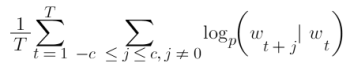
It achieves this by calculating the chance of every phrase being the context, with a given goal phrase. Utilizing the softmax perform, the next calculation compares vector representations of phrases.
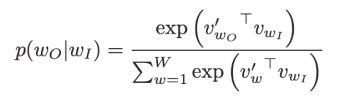
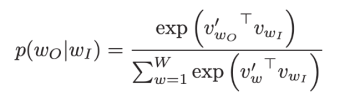
Function Conjugation
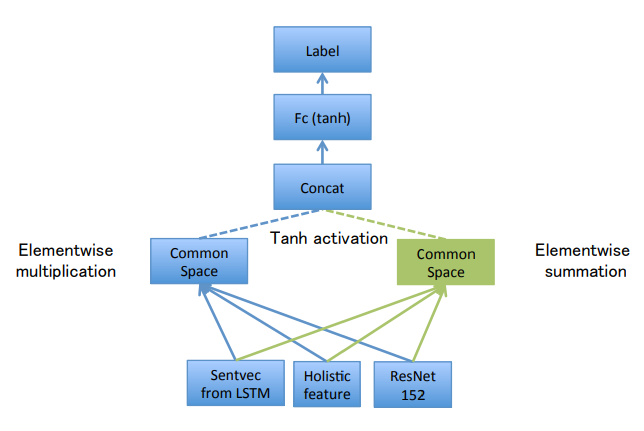
The first distinction between numerous methodologies for VQA lies in combining the picture and textual content options. Some approaches embrace easy concatenation and linear classification. A Bayesian strategy primarily based on probabilistic modeling is preferable for dealing with totally different characteristic vectors.
If the vectors coming from the picture and textual content are of the identical size, element-wise multiplication can also be relevant to hitch the options. You may as well attempt the Consideration-based strategy to information the algorithm’s focus in direction of crucial particulars within the enter. The DualNet VQA mannequin makes use of a hybrid strategy that concatenates element-wise addition and multiplication outcomes to attain better accuracy.
Reply Era
This part in a VQA mannequin includes taking the encoded picture and query options as inputs and producing the ultimate reply. A solution could possibly be in binary type, counting numbers, checking the precise reply, pure language solutions, or open-ended solutions in phrases, phrases, or sentences.
The multiple-choice and binary solutions use a classification layer to transform the mannequin’s output right into a chance rating. LSTMs are applicable to make use of when coping with open-ended questions.
VQA Datasets
A number of datasets are current for VQA analysis. Visible Genome is at the moment the most important accessible dataset for visible query answering fashions.
Relying on the query reply pairs, listed here are among the frequent datasets for VQA.
- COCO-QA Dataset: Extension of COCO (Frequent Objects in Context). Questions of 4 varieties: quantity, shade, object, and placement. Right solutions are all given in a single phrase.
- CLEVR: Incorporates a coaching set of 70,000 photos and 699,989 questions. A validation set of 15,000 photos and 149,991 questions. A take a look at set of 15,000 photos and 14,988 questions. Solutions for all coaching and VAL questions.
- DAQUAR: Include real-world photos. People query reply pairs about photos.
- Visual7W: A big-scale visible query answering dataset with object-level floor reality and multimodal solutions. Every query begins with one of many seven Ws.

Purposes of Visible Query Answering System
Individually, CV and NLP have separate units of assorted purposes. Implementation of each in the identical system can additional improve the applying area for Visible Query Answering.
Actual-world purposes of VQA are:
Medical – VQA
This subdomain focuses on the questions and solutions associated to the medical area. VQA fashions could act as pathologists, radiologists, or correct medical assistants. VQA within the medical sector can vastly scale back the workload of employees by automating a number of duties. For instance, it may well lower the probabilities of illness misdiagnosis.
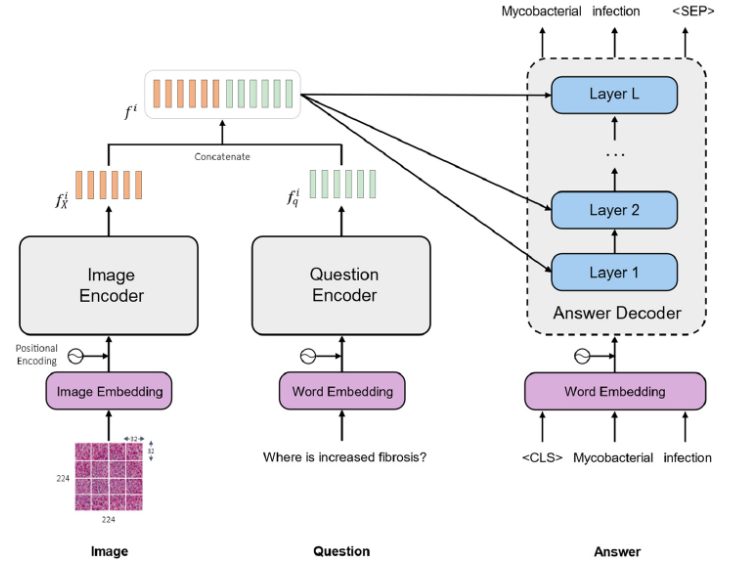
VQA might be carried out as a medical advisor primarily based on photos supplied by the sufferers. It may be used to examine medical information and information accuracy from the database.
Training
The appliance of VQA within the schooling sector can assist visible studying to a fantastic extent. Think about having a studying assistant who can information and consider you with discovered ideas. A few of the proposed use circumstances are Computerized Robotic System for Pre-scholars, Visible Chatbots for Training, Gamification of VQA Programs, and Automated Museum Guides. VQA in schooling has the potential to make studying kinds extra interactive and inventive.
Assistive Expertise
The prime motive behind VQA is to assist visually impaired people. Initiatives just like the VizWiz cell app and Be My Eyes make the most of VQA methods to supply automated help to visually impaired people by answering questions on real-world photos. Assistive VQA fashions can see the environment and assist folks perceive what’s taking place round them.
Visually impaired folks can have interaction extra meaningfully with their setting with the assistance of such VQA methods. Envision Glasses is an instance of such a mannequin.

E-commerce
VQA is able to enhancing the net purchasing consumer expertise. Shops and platforms for on-line purchasing can combine VQA to create a streamlined e-commerce setting. For instance, you’ll be able to ask questions on merchandise (Product Query Answering) and even add photos, and it’ll give you all the required data like product particulars, availability, and even suggestions primarily based on what it sees within the photos.
On-line purchasing shops and web sites can implement VQA as a substitute of guide customer support to additional enhance the consumer expertise on their platforms. It may well assist prospects with:
- Product suggestions
- Troubleshooting for customers
- Web site and purchasing tutorials
- VQA system also can act as a Chatbot that may converse visible dialogues
Content material Filtering
One of the vital appropriate purposes of VQA is content material moderation. Primarily based on its basic characteristic, it may well detect dangerous or inappropriate content material and filter it out to maintain a secure on-line setting. Any offensive or inappropriate content material on social media platforms might be detected utilizing VQA.
Current Growth & Challenges In Enhancing VQA
With the fixed development of CV and DL, VQA fashions are making big progress. The variety of annotated datasets is quickly rising due to crowd-sourcing, and the fashions have gotten clever sufficient to supply an correct reply utilizing pure language. Prior to now few years, many VQA algorithms have been proposed. Virtually each technique includes:
- Picture featurization
- Query featurization
- An acceptable algorithm that mixes these options to generate the reply
Nonetheless, a big hole exists between correct VQA methods and human intelligence. Presently, it’s onerous to develop any adaptable mannequin because of the variety of datasets. It’s troublesome to find out which technique is superior as of but.
Sadly, as a result of most massive datasets don’t provide particular details about the forms of questions requested, it’s onerous to measure how nicely methods deal with sure forms of questions.
The current fashions can’t enhance total efficiency scores when dealing with distinctive questions. This makes it onerous for the evaluation of strategies used for VQA. Presently, a number of selection questions are used to guage VQA algorithms as a result of evaluation of open-ended multi-word questions is difficult. Furthermore, VQA relating to movies nonetheless has a protracted solution to go.
Present algorithms aren’t enough to mark VQA as a solved downside. With out bigger datasets and extra sensible work, it’s onerous to make better-performing VQA fashions.
What’s Subsequent for Visible Query Answering?
VQA is a state-of-the-art AI mannequin that’s rather more than task-specific algorithms. Being an image-understanding mannequin, VQA goes to be a significant improvement in AI. It is bridging the hole between visible content material and pure language.
Textual content-based queries are frequent, however think about interacting with the pc and asking questions on photos or scenes. We’re going to see extra intuitive and pure interactions with computer systems.
Some future suggestions to enhance VQA are:
- Datasets should be bigger
- Datasets should be much less biased
- Future datasets want extra nuanced evaluation for benchmarking
Extra effort is required to create VQA algorithms that may suppose deeply about what’s within the photos.
Associated matters and weblog articles about pc imaginative and prescient and NLP: