TLDR: We suggest the uneven licensed robustness downside, which requires licensed robustness for just one class and displays real-world adversarial situations. This centered setting permits us to introduce feature-convex classifiers, which produce closed-form and deterministic licensed radii on the order of milliseconds.

Determine 1. Illustration of feature-convex classifiers and their certification for sensitive-class inputs. This structure composes a Lipschitz-continuous characteristic map $varphi$ with a discovered convex perform $g$. Since $g$ is convex, it’s globally underapproximated by its tangent aircraft at $varphi(x)$, yielding licensed norm balls within the characteristic house. Lipschitzness of $varphi$ then yields appropriately scaled certificates within the authentic enter house.
Regardless of their widespread utilization, deep studying classifiers are acutely weak to adversarial examples: small, human-imperceptible picture perturbations that idiot machine studying fashions into misclassifying the modified enter. This weak spot severely undermines the reliability of safety-critical processes that incorporate machine studying. Many empirical defenses towards adversarial perturbations have been proposed—usually solely to be later defeated by stronger assault methods. We subsequently deal with certifiably strong classifiers, which give a mathematical assure that their prediction will stay fixed for an $ell_p$-norm ball round an enter.
Typical licensed robustness strategies incur a variety of drawbacks, together with nondeterminism, gradual execution, poor scaling, and certification towards just one assault norm. We argue that these points might be addressed by refining the licensed robustness downside to be extra aligned with sensible adversarial settings.
The Uneven Licensed Robustness Drawback
Present certifiably strong classifiers produce certificates for inputs belonging to any class. For a lot of real-world adversarial functions, that is unnecessarily broad. Think about the illustrative case of somebody composing a phishing rip-off e-mail whereas attempting to keep away from spam filters. This adversary will at all times try and idiot the spam filter into pondering that their spam e-mail is benign—by no means conversely. In different phrases, the attacker is solely trying to induce false negatives from the classifier. Related settings embrace malware detection, faux information flagging, social media bot detection, medical insurance coverage claims filtering, monetary fraud detection, phishing web site detection, and lots of extra.
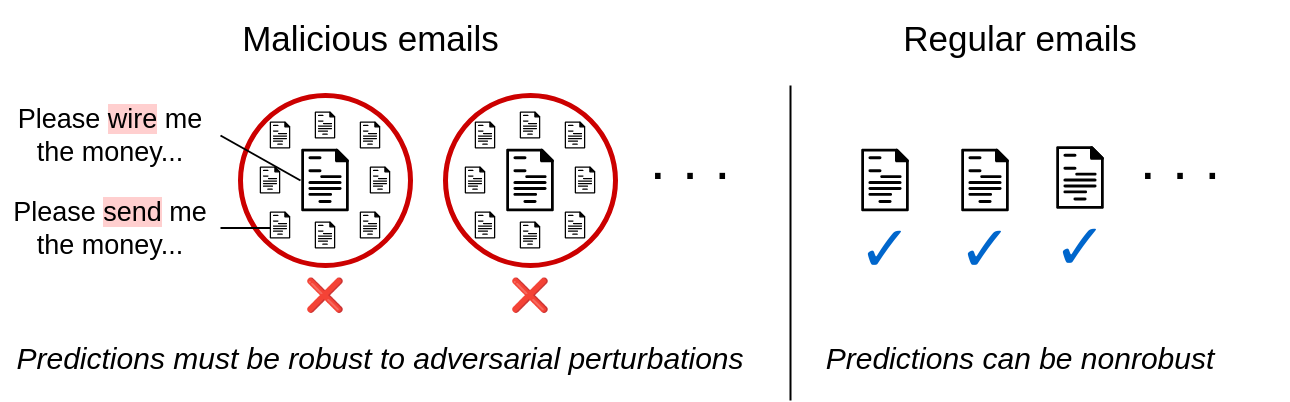
Determine 2. Uneven robustness in e-mail filtering. Sensible adversarial settings usually require licensed robustness for just one class.
These functions all contain a binary classification setting with one delicate class that an adversary is trying to keep away from (e.g., the “spam e-mail” class). This motivates the issue of uneven licensed robustness, which goals to offer certifiably strong predictions for inputs within the delicate class whereas sustaining a excessive clear accuracy for all different inputs. We offer a extra formal downside assertion in the primary textual content.
Function-convex classifiers
We suggest feature-convex neural networks to handle the uneven robustness downside. This structure composes a easy Lipschitz-continuous characteristic map ${varphi: mathbb{R}^d to mathbb{R}^q}$ with a discovered Enter-Convex Neural Community (ICNN) ${g: mathbb{R}^q to mathbb{R}}$ (Determine 1). ICNNs implement convexity from the enter to the output logit by composing ReLU nonlinearities with nonnegative weight matrices. Since a binary ICNN choice area consists of a convex set and its complement, we add the precomposed characteristic map $varphi$ to allow nonconvex choice areas.
Function-convex classifiers allow the quick computation of sensitive-class licensed radii for all $ell_p$-norms. Utilizing the truth that convex features are globally underapproximated by any tangent aircraft, we are able to get hold of a licensed radius within the intermediate characteristic house. This radius is then propagated to the enter house by Lipschitzness. The uneven setting right here is essential, as this structure solely produces certificates for the positive-logit class $g(varphi(x)) > 0$.
The ensuing $ell_p$-norm licensed radius formulation is especially elegant:
[r_p(x) = frac{ color{blue}{g(varphi(x))} } { mathrm{Lip}_p(varphi) color{red}{| nabla g(varphi(x)) | _{p,*}}}.]
The non-constant phrases are simply interpretable: the radius scales proportionally to the classifier confidence and inversely to the classifier sensitivity. We consider these certificates throughout a variety of datasets, reaching aggressive $ell_1$ certificates and comparable $ell_2$ and $ell_{infty}$ certificates—regardless of different strategies usually tailoring for a selected norm and requiring orders of magnitude extra runtime.
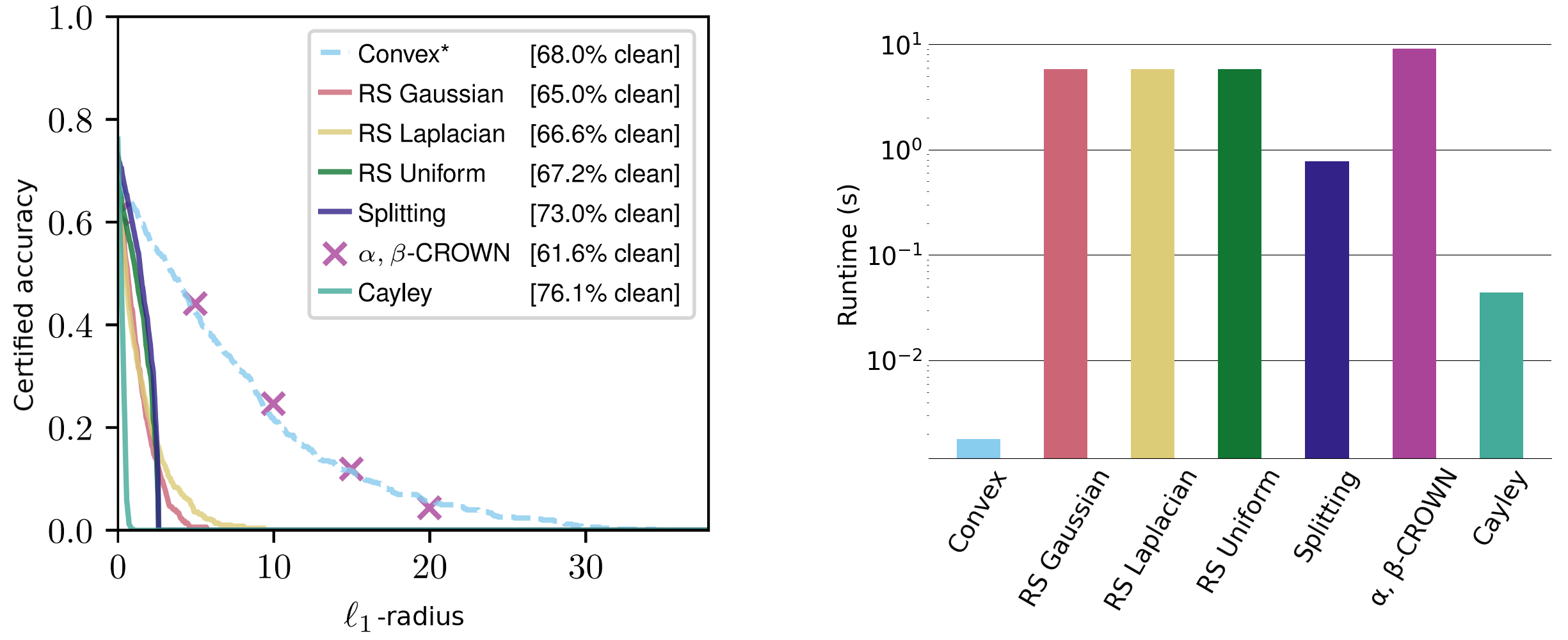
Determine 3. Delicate class licensed radii on the CIFAR-10 cats vs canine dataset for the $ell_1$-norm. Runtimes on the precise are averaged over $ell_1$, $ell_2$, and $ell_{infty}$-radii (be aware the log scaling).
Our certificates maintain for any $ell_p$-norm and are closed kind and deterministic, requiring only one forwards and backwards cross per enter. These are computable on the order of milliseconds and scale nicely with community dimension. For comparability, present state-of-the-art strategies reminiscent of randomized smoothing and interval sure propagation sometimes take a number of seconds to certify even small networks. Randomized smoothing strategies are additionally inherently nondeterministic, with certificates that simply maintain with excessive likelihood.
Theoretical promise
Whereas preliminary outcomes are promising, our theoretical work suggests that there’s vital untapped potential in ICNNs, even with out a characteristic map. Regardless of binary ICNNs being restricted to studying convex choice areas, we show that there exists an ICNN that achieves good coaching accuracy on the CIFAR-10 cats-vs-dogs dataset.
Reality. There exists an input-convex classifier which achieves good coaching accuracy for the CIFAR-10 cats-versus-dogs dataset.
Nonetheless, our structure achieves simply $73.4%$ coaching accuracy with out a characteristic map. Whereas coaching efficiency doesn’t suggest check set generalization, this outcome means that ICNNs are at the very least theoretically able to attaining the trendy machine studying paradigm of overfitting to the coaching dataset. We thus pose the next open downside for the sector.
Open downside. Be taught an input-convex classifier which achieves good coaching accuracy for the CIFAR-10 cats-versus-dogs dataset.
Conclusion
We hope that the uneven robustness framework will encourage novel architectures that are certifiable on this extra centered setting. Our feature-convex classifier is one such structure and gives quick, deterministic licensed radii for any $ell_p$-norm. We additionally pose the open downside of overfitting the CIFAR-10 cats vs canine coaching dataset with an ICNN, which we present is theoretically potential.
This put up is predicated on the next paper:
Uneven Licensed Robustness by way of Function-Convex Neural Networks
Samuel Pfrommer,
Brendon G. Anderson,
Julien Piet,
Somayeh Sojoudi,
thirty seventh Convention on Neural Data Processing Techniques (NeurIPS 2023).
Additional particulars can be found on arXiv and GitHub. If our paper evokes your work, please contemplate citing it with:
@inproceedings{
pfrommer2023asymmetric,
title={Uneven Licensed Robustness by way of Function-Convex Neural Networks},
writer={Samuel Pfrommer and Brendon G. Anderson and Julien Piet and Somayeh Sojoudi},
booktitle={Thirty-seventh Convention on Neural Data Processing Techniques},
yr={2023}
}