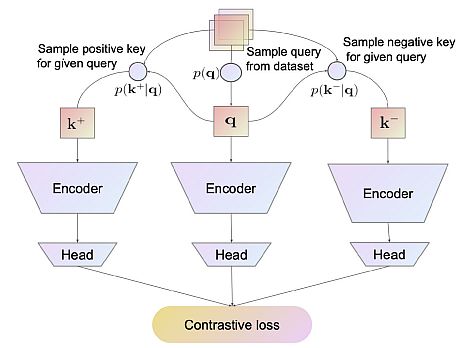
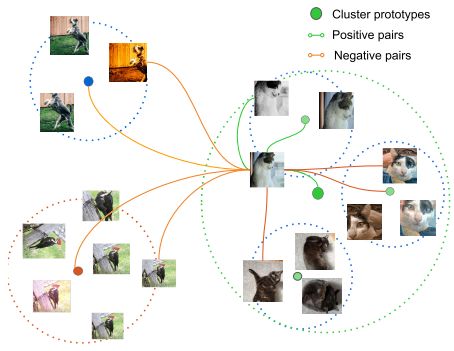
The objective of contrastive studying is to extract significant representations by evaluating pairs of optimistic and unfavourable cases. It assumes that dissimilar instances ought to be farther aside and put the comparable cases nearer within the studying embedding area.
Contrastive studying (CL) permits fashions to determine pertinent traits and similarities within the information by presenting studying as a discrimination job. In different phrases, samples from the identical distribution are pushed other than each other within the embedding area. As well as, samples from different distributions are pulled to at least one one other.
About us: Viso Suite makes it doable for enterprises to seamlessly implement visible AI options into their workflows. From crowd monitoring to defect detection to letter and quantity recognition, Viso Suite is customizable to suit the precise necessities of any utility. To study extra about what Viso Suite can do in your group, ebook a demo with our workforce of consultants.
The Advantages of Contrastive Studying
Fashions can derive significant representations from unlabeled information by contrastive studying. Contrastive studying permits fashions to separate dissimilar cases whereas mapping comparable ones shut collectively by using similarity and dissimilarity.
This technique has proven promise in a wide range of fields, together with reinforcement studying, pc imaginative and prescient, and pure language processing (NLP).
The advantages of contrastive studying embody:
- Utilizing similarity and dissimilarity to map cases in a latent area, CL is a potent technique for extracting significant representations from unlabeled information.
- Contrastive studying enhances mannequin efficiency and generalization in a variety of purposes, together with information augmentation, supervised studying, semi-supervised studying, and NLP.
- Knowledge augmentation, encoders, and projection networks are essential components that seize pertinent traits and parallels.
- It contains each self-supervised contrastive studying (SCL) with unlabeled information and supervised contrastive studying (SSCL) with labeled information.
- Contrastive studying employs completely different loss features: Logistic loss, N-pair loss, InfoNCE, Triplet, and Contrastive loss.
Methods to Implement Contrastive Studying?
Contrastive studying is a potent technique that allows fashions to make use of huge portions of unlabeled information whereas nonetheless enhancing efficiency with a small amount of labeled information.
The primary objective of contrastive studying is to drive dissimilar samples farther away and map comparable cases nearer in a realized embedding area. To implement CL it’s a must to carry out information augmentation and prepare the encoder and projection community.
Knowledge Augmentation
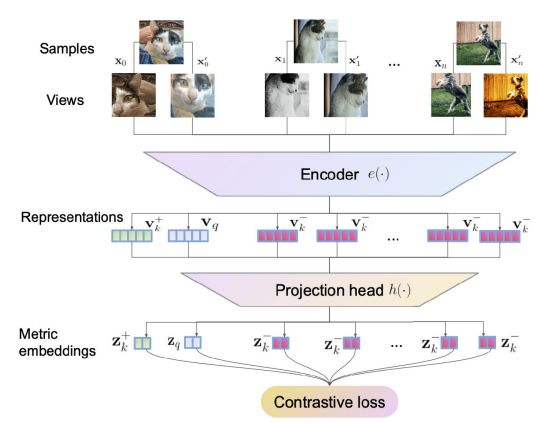
The objective of information augmentation is to reveal the mannequin to a number of viewpoints on the identical occasion and enhance the info variations. Knowledge augmentation creates numerous cases or augmented views by making use of completely different transformations (perturbations) to unlabeled information. It’s typically step one in contrastive studying.

Cropping, flipping, rotation, random cropping, and shade adjustments are examples of frequent information augmentation methods. Contrastive studying ensures that the mannequin learns to gather pertinent info regardless of enter information adjustments by producing numerous cases.
Encoder and Projection Community
Coaching an encoder community is the subsequent stage of contrastive studying. The augmented cases are fed into the encoder community, which then maps them to a latent illustration area the place vital similarities and options are recorded.
Often, the encoder community is a deep neural community, like a recurrent neural community (RNN) for sequential information or a CNN for visible information.
The realized representations are additional refined utilizing a projection community. The output of the encoder community is projected onto a lower-dimensional area, also called the projection or embedding area (a projection community).
The projection community makes the info easier and redundant by projecting the representations to a lower-dimensional area, which makes it simpler to tell apart between related and dissimilar cases.
Coaching and Optimization
After the loss perform has been established, a big unlabeled dataset is used to coach the mannequin. The mannequin’s parameters are iteratively up to date in the course of the coaching part to attenuate the loss perform.
The mannequin’s hyperparameters are often adjusted utilizing optimization strategies like stochastic gradient descent (SGD) or variations. Moreover, batch measurement updates are used for coaching, processing a portion of augmented cases without delay.
Throughout coaching, the mannequin good points the power to determine pertinent traits and patterns within the information. The iterative optimization course of ends in higher discrimination and separation between related and completely different cases, which additionally improves the realized representations.
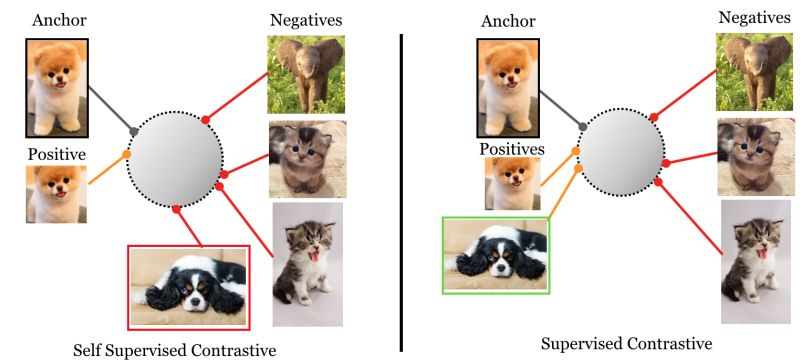
Supervised vs Self-supervised CL
The sphere of supervised contrastive studying (SCL) systematically trains fashions to tell apart between related and dissimilar cases utilizing labeled information. Pairs of knowledge factors and their labels – which point out whether or not the info factors are related or dissimilar, are used to coach the mannequin in SCL.
The mannequin good points the power to tell apart between related and dissimilar instances by maximizing this objective, which reinforces efficiency on subsequent challenges.
A unique technique is self-supervised contrastive studying (SSCL), which doesn’t depend on express class labels however as an alternative learns representations from unlabeled information. Pretext duties might help SSCL to generate optimistic and unfavourable pairings from the unlabeled information.
The aim of those well-crafted pretext assignments is to inspire the mannequin to determine vital traits and patterns within the information.
SSCL has demonstrated exceptional outcomes in a number of fields, together with pure language processing and pc imaginative and prescient. SSCL can also be profitable in pc imaginative and prescient duties equivalent to object identification and picture classification issues.
Loss Capabilities in CL
Contrastive studying makes use of a number of loss features to specify the studying course of’s objectives. These loss features let the mannequin distinguish between related and dissimilar cases and seize significant representations.
To determine pertinent traits and patterns within the information and enhance the mannequin’s capability, we should always know the assorted loss features employed in contrastive studying.
Triplet Loss
A standard loss perform utilized in contrastive studying is triplet loss. Preserving the Euclidean distances between cases is its objective. Triplet loss is the method of making triplets of cases: a foundation occasion, a unfavourable pattern that’s dissimilar from the premise, and a optimistic pattern that’s similar to the premise.
The objective is to ensure that, by a predetermined margin, the space between the premise and the optimistic pattern is lower than the space between the premise and the unfavourable pattern.
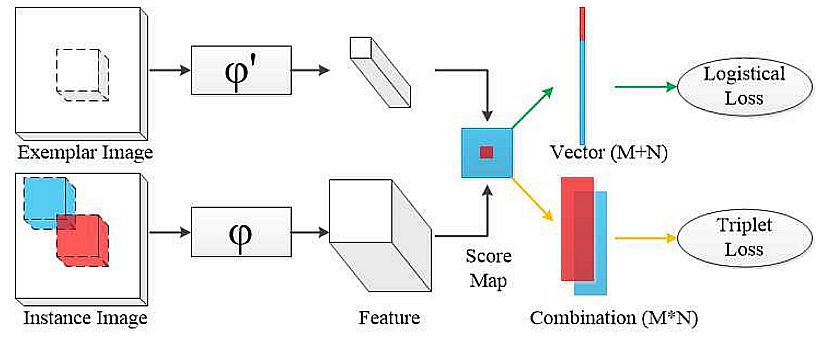
Triplet loss may be very helpful in pc imaginative and prescient duties the place amassing fine-grained similarities is important, e.g. face recognition and picture retrieval. Nonetheless, as a result of deciding on significant triplets from coaching information will be tough and computationally expensive, triplet loss could also be delicate to triplet choice.
N-pair Loss
An enlargement of triplet loss, N-pair loss considers a number of optimistic and unfavourable samples for a selected foundation occasion. N-pair loss tries to maximise the similarity between the premise and all optimistic cases whereas lowering the similarity between the premise and all unfavourable cases. It doesn’t evaluate a foundation occasion to a single optimistic (unfavourable) pattern.
N-pair loss supplies sturdy supervision studying, which pushes the mannequin to know delicate correlations amongst quite a few samples. It enhances the discriminative energy of the realized representations and might seize extra intricate patterns by considering many cases without delay.
N-pair loss has purposes in a number of duties, e.g. picture recognition, the place figuring out delicate variations amongst related cases is essential. By using a wide range of each optimistic and unfavourable samples it mitigates among the difficulties associated to triplet loss.
Contrastive Loss
One of many fundamental loss features in contrastive studying is contrastive loss. Within the realized embedding area, it seeks to cut back the settlement between cases from separate samples and maximize the settlement between optimistic pairs (cases from the identical pattern).
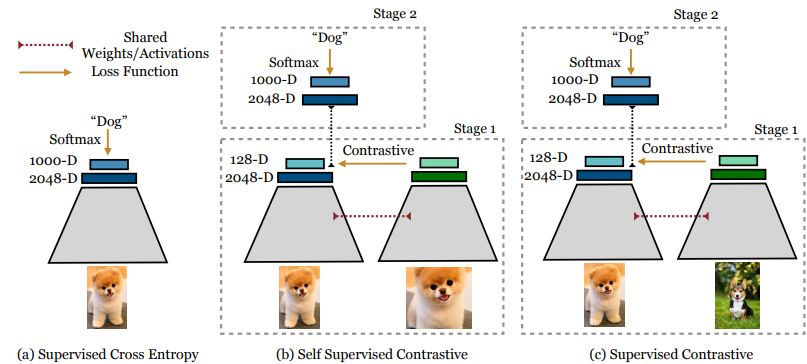
The contrastive loss perform is a margin-based loss by which a distance metric, and measures how related two examples are. To calculate the contrastive loss – researchers penalized optimistic samples for being too far aside and unfavourable samples for being too shut within the embedding area.
Contrastive loss is environment friendly in a wide range of fields, together with pc imaginative and prescient and pure language processing. Furthermore, it pushes the mannequin to develop discriminative representations that seize vital similarities and variations.
Contrastive Studying Frameworks
Many contrastive studying frameworks have been well-known in deep studying lately due to their effectivity in studying potent representations. Right here we’ll elaborate on the most well-liked contrastive studying frameworks:
NNCLR
The Nearest-Neighbor Contrastive Studying (NNCLR) framework makes an attempt to make use of completely different pictures from the identical class, as an alternative of augmenting the identical picture. In reverse, most strategies deal with completely different views of the identical picture as positives for a contrastive loss.
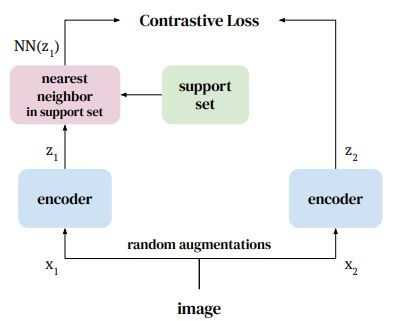
By sampling the dataset’s nearest neighbors within the latent area and utilizing them as optimistic samples, the NNCLR mannequin produces a extra different number of optimistic pairs. It additionally improves the mannequin’s studying capabilities.
Much like the SimCLR framework, NNCLR employs the InfoNCE loss. Nonetheless, the optimistic pattern is now the premise picture’s closest neighbor.
SimCLR
The efficacy of the self-supervised contrastive studying framework Easy Contrastive Studying of Representations (SimCLR) in studying representations is reasonably excessive. By using a symmetric neural community structure, a well-crafted contrastive intention, and information augmentation, it expands on the concepts of contrastive studying.
SimCLR’s foremost objective is to attenuate the settlement between views from numerous cases. Additionally, it maximizes the settlement between augmented views of the identical occasion. To offer efficient and environment friendly contrastive studying, the system makes use of a large-batch coaching method.
In a number of fields, equivalent to CV, NLP, and reinforcement studying, SimCLR has proven excellent efficiency. It demonstrates its efficacy in studying potent representations by outperforming earlier approaches in numerous benchmark datasets and duties.
BYOL
Bootstrap Your Personal Latent (BYOL) updates the goal community parameters within the self-supervised contrastive studying framework on-line. Utilizing a pair of on-line and goal networks, it updates the goal community by taking exponential shifting averages of the weights within the on-line community. BYOL additionally emphasizes studying representations with out requiring unfavorable examples.
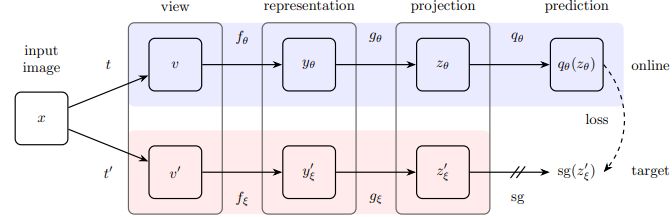
The method decouples the similarity estimation from unfavourable samples whereas optimizing settlement between enhanced views of the identical occasion. In a number of fields, equivalent to pc imaginative and prescient and NLP, BYOL has proven exceptional efficiency. As well as, it has produced state-of-the-art outcomes and demonstrated notable enhancements in illustration high quality.
CV Functions of Contrastive Studying
Contrastive Studying has been efficiently utilized within the subject of pc imaginative and prescient. The primary purposes embody:
- Object Detection: a contrastive self-supervised technique for object detection employs two methods: 1) multi-level supervision to intermediate representations, and a pair of) contrastive studying between the worldwide picture and native patches.
- Semantic Segmentation: making use of contrastive studying for the segmentation of actual pictures. It makes use of supervised contrastive loss to pre-train a mannequin and the traditional cross-entropy for fine-tuning.
- Video Sequence Prediction: The mannequin employs a contrastive machine studying algorithm for unsupervised illustration studying. Engineers make the most of among the sequence’s frames to reinforce the coaching set as optimistic/unfavourable pairs.
- Distant Sensing: The mannequin employs a self-supervised pre-train and supervised fine-tuning method to phase information from distant sensing pictures.
What’s Subsequent?
Immediately, contrastive studying is gaining reputation as a way for bettering present supervised and self-supervised studying approaches. Strategies primarily based on contrastive studying have improved efficiency on duties involving illustration studying and semi-supervised studying.
Its fundamental concept is to check samples from a dataset and push or pull representations within the unique pictures in keeping with whether or not the samples are a part of the identical or completely different distribution (e.g., the identical object in object detection duties, or class in classification fashions).
Often Requested Questions
Q1: How does contrastive studying work?
Reply: Contrastive studying drives dissimilar samples farther away and maps comparable cases nearer in a realized embedding area.
Q2: What’s the objective of the loss features in contrastive studying?
Reply: Loss features specify the objectives of the machine studying mannequin. They let the mannequin distinguish between related and dissimilar cases and seize significant representations.
Q3: What are the primary frameworks for contrastive studying?
Reply: The primary frameworks for contrastive studying embody Nearest-Neighbor Contrastive Studying (NNCLR), SimCLR, and Bootstrap Your Personal Latent (BYOL).
This fall: What are the purposes of contrastive studying in pc imaginative and prescient?
Reply: The purposes of contrastive studying in pc imaginative and prescient embody object detection, semantic segmentation, distant sensing, and video sequence prediction.