Have you ever ever questioned how search engines like google and yahoo perceive your queries, even whenever you use completely different phrase kinds? Or how chatbots comprehend and reply precisely, regardless of variations in language?
The reply lies in Pure Language Processing (NLP), an interesting department of synthetic intelligence that permits machines to grasp and course of human language.
One of many key methods in NLP is lemmatization, which refines textual content processing by lowering phrases to their base or dictionary kind. Not like easy phrase truncation, lemmatization takes context and which means into consideration, making certain extra correct language interpretation.
Whether or not it’s enhancing search outcomes, enhancing chatbot interactions, or aiding textual content evaluation, lemmatization performs an important function in a number of purposes.
On this article, we’ll discover what lemmatization is, the way it differs from stemming, its significance in NLP, and how one can implement it in Python. Let’s dive in!
What’s Lemmatization?
Lemmatization is the method of changing a phrase to its base kind (lemma) whereas contemplating its context and which means. Not like stemming, which merely removes suffixes to generate root phrases, lemmatization ensures that the reworked phrase is a sound dictionary entry. This makes lemmatization extra correct for textual content processing.
For instance:
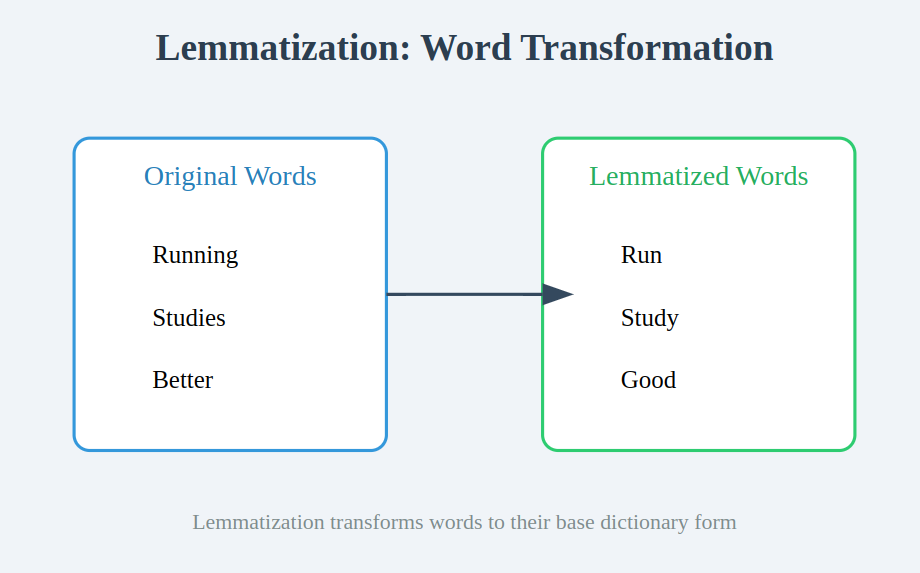
- Working → Run
- Research → Examine
- Higher → Good (Lemmatization considers which means, in contrast to stemming)
Additionally Learn: What’s Stemming in NLP?
How Lemmatization Works
Lemmatization usually includes:
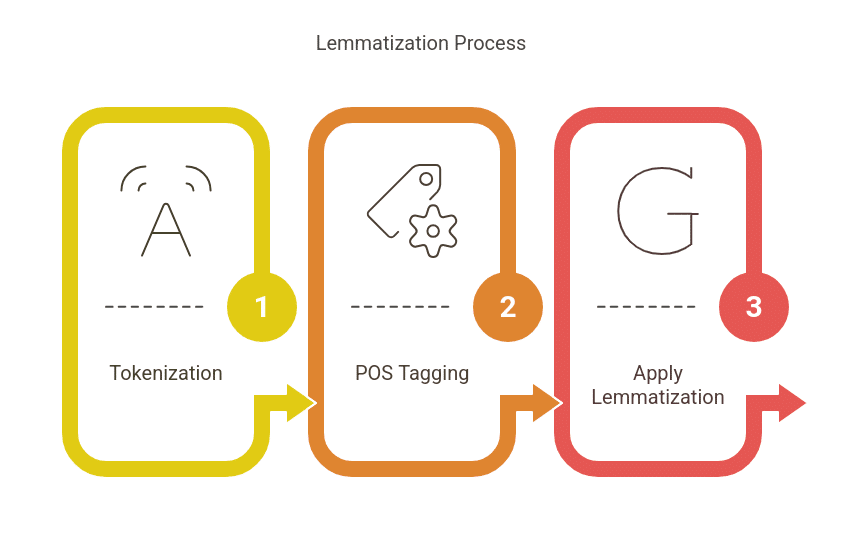
- Tokenization: Splitting textual content into phrases.
- Instance: Sentence: “The cats are enjoying within the backyard.”
- After tokenization: [‘The’, ‘cats’, ‘are’, ‘playing’, ‘in’, ‘the’, ‘garden’]
- Half-of-Speech (POS) Tagging: Figuring out a phrase’s function (noun, verb, adjective, and so forth.).
- Instance: cats (noun), are (verb), enjoying (verb), backyard (noun)
- POS tagging helps distinguish between phrases with a number of kinds, corresponding to “working” (verb) vs. “working” (adjective, as in “working water”).
- Making use of Lemmatization Guidelines: Changing phrases into their base kind utilizing a lexical database.
- Instance:
- enjoying → play
- cats → cat
- higher → good
- With out POS tagging, “enjoying” may not be lemmatized accurately. POS tagging ensures that “enjoying” is accurately reworked into “play” as a verb.
- Instance:
Instance 1: Normal Verb Lemmatization
Take into account a sentence: “She was working and had studied all evening.”
- With out lemmatization: [‘was’, ‘running’, ‘had’, ‘studied’, ‘all’, ‘night’]
- With lemmatization: [‘be’, ‘run’, ‘have’, ‘study’, ‘all’, ‘night’]
- Right here, “was” is transformed to “be”, “working” to “run”, and “studied” to “examine”, making certain the bottom kinds are acknowledged.
Instance 2: Adjective Lemmatization
Take into account: “That is one of the best answer to a greater downside.”
- With out lemmatization: [‘best’, ‘solution’, ‘better’, ‘problem’]
- With lemmatization: [‘good’, ‘solution’, ‘good’, ‘problem’]
- Right here, “greatest” and “higher” are diminished to their base kind “good” for correct which means illustration.
Why is Lemmatization Necessary in NLP?
Lemmatization performs a key function in enhancing textual content normalization and understanding. Its significance consists of:
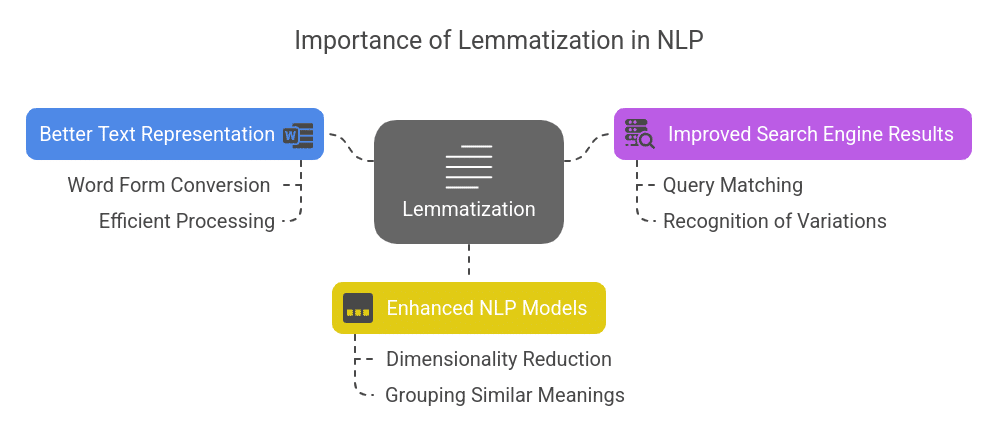
- Higher Textual content Illustration: Converts completely different phrase kinds right into a single kind for environment friendly processing.
- Improved Search Engine Outcomes: Helps search engines like google and yahoo match queries with related content material by recognizing completely different phrase variations.
- Enhanced NLP Fashions: Reduces dimensionality in machine studying and NLP duties by grouping phrases with comparable meanings.
Learn the way Textual content Summarization in Python works and discover methods like extractive and abstractive summarization to condense massive texts effectively.
Lemmatization vs. Stemming
Each lemmatization and stemming goal to cut back phrases to their base kinds, however they differ in strategy and accuracy:
| Characteristic | Lemmatization | Stemming |
| Strategy | Makes use of linguistic data and context | Makes use of easy truncation guidelines |
| Accuracy | Excessive (produces dictionary phrases) | Decrease (could create non-existent phrases) |
| Processing Pace | Slower because of linguistic evaluation | Sooner however much less correct |

Implementing Lemmatization in Python
Python supplies libraries like NLTK and spaCy for lemmatization.
Utilizing NLTK:
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet
import nltk
nltk.obtain('wordnet')
nltk.obtain('omw-1.4')
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("working", pos="v")) # Output: run
Utilizing spaCy:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("working research higher")
print([token.lemma_ for token in doc]) # Output: ['run', 'study', 'good']
Purposes of Lemmatization
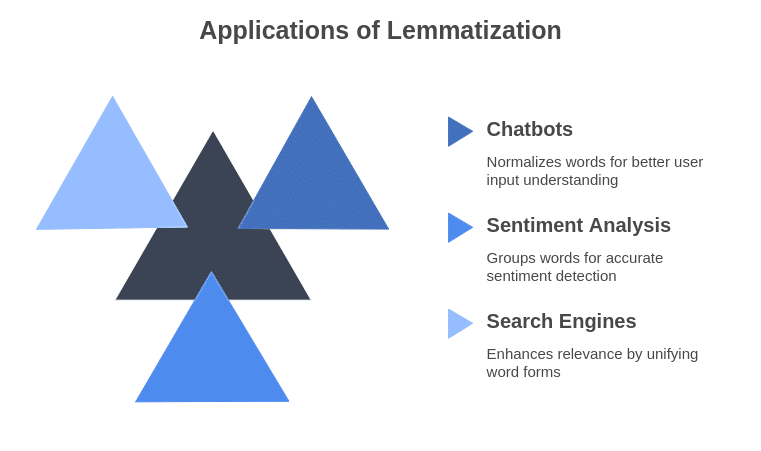
- Chatbots & Digital Assistants: Understands person inputs higher by normalizing phrases.
- Sentiment Evaluation: Teams phrases with comparable meanings for higher sentiment detection.
- Search Engines: Enhances search relevance by treating completely different phrase kinds as the identical entity.
Advised: Free NLP Programs
Challenges of Lemmatization
- Computational Value: Slower than stemming because of linguistic processing.
- POS Tagging Dependency: Requires right tagging to generate correct outcomes.
- Ambiguity: Some phrases have a number of legitimate lemmas based mostly on context.
Future Developments in Lemmatization
With developments in AI and NLP , lemmatization is evolving with:
- Deep Studying-Based mostly Lemmatization: Utilizing transformer fashions like BERT for context-aware lemmatization.
- Multilingual Lemmatization: Supporting a number of languages for world NLP purposes.
- Integration with Giant Language Fashions (LLMs): Enhancing accuracy in conversational AI and textual content evaluation.
Conclusion
Lemmatization is an important NLP method that refines textual content processing by lowering phrases to their dictionary kinds. It improves the accuracy of NLP purposes, from search engines like google and yahoo to chatbots. Whereas it comes with challenges, its future appears to be like promising with AI-driven enhancements.
By leveraging lemmatization successfully, companies and builders can improve textual content evaluation and construct extra clever NLP options.
Grasp NLP and lemmatization methods as a part of the PG Program in Synthetic Intelligence & Machine Studying.
This program dives deep into AI purposes, together with Pure Language Processing and Generative AI, serving to you construct real-world AI options. Enroll at present and benefit from expert-led coaching and hands-on initiatives.
Regularly Requested Questions(FAQ’s)
What’s the distinction between lemmatization and tokenization in NLP?
Tokenization breaks textual content into particular person phrases or phrases, whereas lemmatization converts phrases into their base kind for significant language processing.
How does lemmatization enhance textual content classification in machine studying?
Lemmatization reduces phrase variations, serving to machine studying fashions establish patterns and enhance classification accuracy by normalizing textual content enter.
Can lemmatization be utilized to a number of languages?
Sure, fashionable NLP libraries like spaCy and Stanza assist multilingual lemmatization, making it helpful for various linguistic purposes.
Which NLP duties profit probably the most from lemmatization?
Lemmatization enhances search engines like google and yahoo, chatbots, sentiment evaluation, and textual content summarization by lowering redundant phrase kinds.
Is lemmatization all the time higher than stemming for NLP purposes?
Whereas lemmatization supplies extra correct phrase representations, stemming is quicker and could also be preferable for duties that prioritize pace over precision.