Object detection is among the essential duties in Pc Imaginative and prescient (CV). The YOLOv6 mannequin localizes a piece inside a picture and classifies the marked area inside a predefined class. The output of the thing detection is usually a bounding field and a label.
Pc imaginative and prescient researchers launched YOLO structure (You Solely Look As soon as) as an object-detection algorithm in 2015. It was a single-pass algorithm having just one neural community to foretell bounding packing containers and sophistication possibilities utilizing a full picture as enter.
About Us: At viso.ai, we energy Viso Suite, probably the most full end-to-end laptop imaginative and prescient platform. We offer all the pc imaginative and prescient providers and AI imaginative and prescient expertise you’ll want. Get in contact with our group of AI specialists and schedule a demo to see the important thing options.

What’s YOLOv6?
In September 2022, C. Li, L. Li, H. Jiang, et al. (Meituan Inc.) revealed the YOLOv6 paper. Their purpose was to create a single-stage object-detection mannequin for trade functions.
They launched quantization strategies to spice up inference velocity with out efficiency degradation, together with Put up-Coaching Quantization (PTQ) and Quantization-Consciousness Coaching (QAT). These strategies had been utilized in YOLOv6 to attain the purpose of deployment-ready networks.
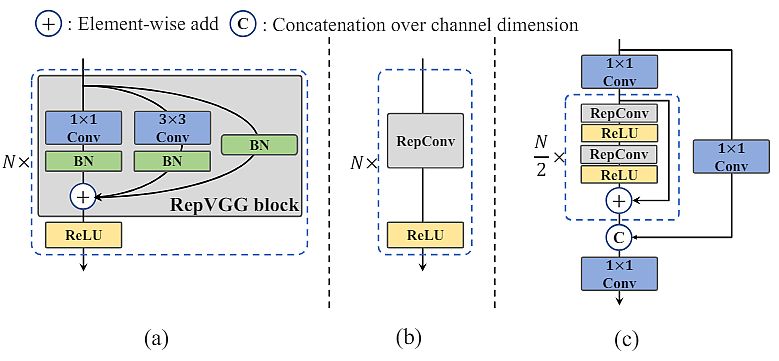
The researchers designed an environment friendly re-parameterizable spine denoted as EfficientRep. For small fashions, the primary element of the spine is RepBlock in the course of the coaching section. In the course of the inference section, they transformed every RepBlock to three×3 convolutional layers (RepConv) with ReLU activation capabilities.
YOLO Model Historical past
YOLOv1
YOLOv1 structure surpassed R-CNN with a imply common precision (mAP) of 63.4, and an inference velocity of 45 FPS on the open-source Pascal VOC 2007 dataset. The mannequin treats object detection as a regression process to foretell bounding packing containers and sophistication possibilities from a single go of a picture.
YOLOv2
Launched in 2016, it might detect 9000+ object classes. YOLOv2 launched anchor packing containers, predefined bounding packing containers referred to as priors that the mannequin makes use of to pin down the best place of an object. YOLOv2 achieved 76.8 mAP at 67 FPS on the Pascal VOC 2007 dataset.
YOLOv3
The authors launched YOLOv3 in 2018 which boasted larger accuracy than the earlier variations, with an mAP of 28.2 at 22 milliseconds. To foretell lessons, the YOLOv3 mannequin makes use of Darknet-53 because the spine with logistic classifiers. It doesn’t use softmax and Binary Cross-entropy (BCE) loss.
YOLOv4
Alexey Bochkovskiy et al. (2020) launched YOLOv4, introducing the idea of a Bag of Freebies (BoF) and a Bag of Specials (BoS). BoF is an information augmentation approach set that will increase accuracy at no extra inference value. BoS considerably enhances accuracy with a slight enhance in value. The mannequin achieved 43.5 mAP at 65 FPS on the COCO dataset.
YOLOv5
With out an official analysis paper, Ultralytics launched YOLOv5 in 2020, the identical 12 months YOLOv4 was launched. The mannequin is simple to coach since it’s applied in PyTorch. The structure makes use of a Cross-stage Partial (CSP) Connection block because the spine for a greater gradient movement to cut back computational value. YOLOv5 makes use of YAML recordsdata as a substitute of CFG recordsdata within the mannequin dimension configurations.
YOLOv6
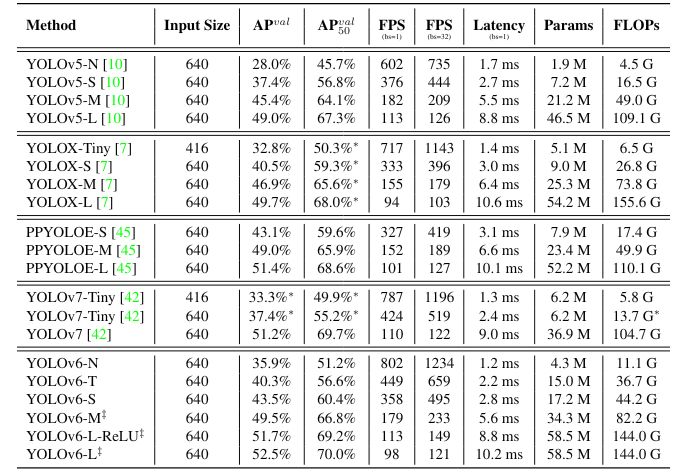
YOLOv6 is one other unofficial model launched in 2022 by Meituan, a Chinese language buying platform. The corporate focused the mannequin for industrial functions with higher efficiency than its predecessor. The adjustments resulted in YOLOv6(nano) reaching an mAP of 37.5 at 1187 FPS on the COCO dataset. The small YOLOv6 mannequin achieved 45 mAP at 484 FPS.
YOLOv7
In July 2022, a gaggle of researchers launched the open-source mannequin YOLOv7. It’s the quickest and probably the most correct object detector with an mAP of 56.8% at FPS starting from 5 to 160. YOLOv7 is predicated on the Prolonged Environment friendly Layer Aggregation Community (E-ELAN). It improves coaching by enabling the mannequin to study various options with environment friendly computation.
YOLOv8
The mannequin YOLOv8 has no official paper (as with YOLOv5 and v6) however boasts larger accuracy and sooner velocity. As an illustration, the YOLOv8(medium) has a 50.2 mAP rating at 1.83 milliseconds on the MS COCO dataset and A100 TensorRT. YOLO v8 additionally incorporates a Python bundle and CLI-based implementation, making it simple to make use of and develop.
YOLOv9
YOLOv9 is the newest model of YOLO, launched in February 2024, by C.Y. Wang, I.H. Yeh, and H.Y.M. Liao. It’s an improved real-time object detection mannequin. To enhance accuracy, researchers utilized programmable gradient data (PGI) and the Generalized Environment friendly Layer Aggregation Community (GELAN).
YOLOv6 Structure
YOLOv6 structure consists of the next elements: a spine, a neck, and a head. The spine primarily determines the characteristic illustration capability. Moreover, its design has a essential affect on the run inference effectivity because it carries a big portion of computation value.
The neck’s objective is to combination the low-level bodily options with high-level semantic options and construct up pyramid characteristic maps in any respect ranges. The top consists of a number of convolutional layers and predicts closing detection outcomes in keeping with multi-level options assembled by the neck.
Furthermore, its construction is anchor-based and anchor-free, or parameter-coupled head and parameter-decoupled head.

Based mostly on the precept of hardware-friendly community design, researchers proposed two scaled re-parameterizable backbones and necks to accommodate fashions of various sizes. Additionally, they launched an environment friendly decoupled head with the hybrid-channel technique. The general structure of YOLOv6 is proven within the determine above.
Efficiency of YOLOv6
Researchers used the identical optimizer and studying schedule as YOLOv5, i.e. Stochastic Gradient Descent (SGD) with momentum and cosine decay on the training price. Additionally, they utilized a warm-up, grouped weight decay technique, and the Exponential Shifting Common (EMA).
They adopted two robust knowledge augmentations (Mosaic and Mixup) following earlier YOLO variations. An entire record of hyperparameter settings is positioned in GitHub. They educated the mannequin on the COCO 2017 coaching set and evaluated the accuracy of the COCO 2017 validation set.
The researchers utilized eight NVIDIA A100 GPUs for coaching. As well as, they measured the velocity efficiency of an NVIDIA Tesla T4 GPU with TensorRT model 7.2.
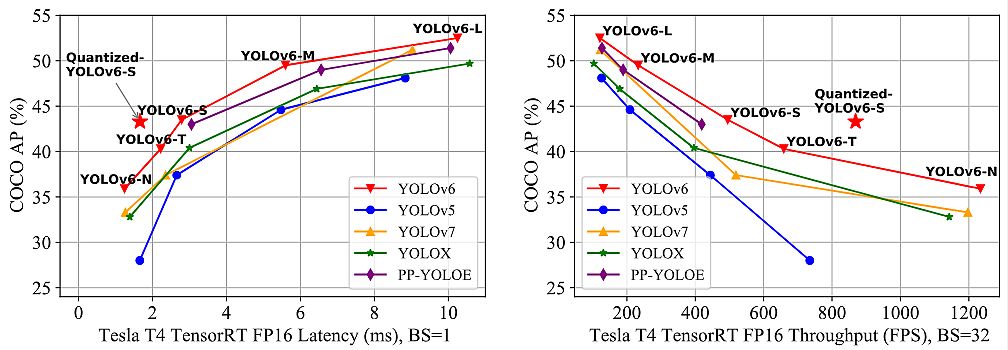
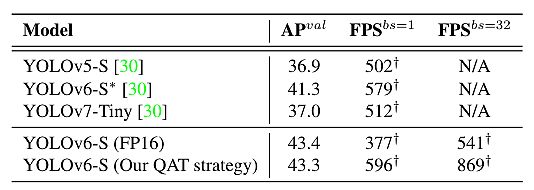
- The developed YOLOv6-N achieves 35.9% AP on the COCO dataset at a throughput of 1234 FPS on an NVIDIA Tesla T4 GPU.
- YOLOv6-S strikes 43.5% AP at 495 FPS, outperforming different mainstream detectors on the identical scale (YOLOv5-S, YOLOX-S, and PPYOLOE-S).
- The quantized model of YOLOv6-S even brings a brand new state-of-the-art 43.3% AP at 869 FPS.
- Moreover, YOLOv6-M/L achieves higher accuracy efficiency (i.e., 49.5%/52.3%) than different detectors with comparable inference speeds.
Business-Associated Enhancements
The authors launched extra widespread practices and tips to enhance the efficiency together with self-distillation and extra coaching epochs.
- For self-distillation, they used the trainer mannequin to oversee each classification and field regression loss. They applied the distillation of field regression utilizing DFL (device-free localization).
- As well as, the proportion of knowledge from the tender and onerous labels dynamically declined through cosine decay. This helped them selectively purchase data at completely different phases in the course of the coaching course of.
- Furthermore, they encountered the issue of impaired efficiency with out including additional grey borders at analysis, for which they offered some treatments.
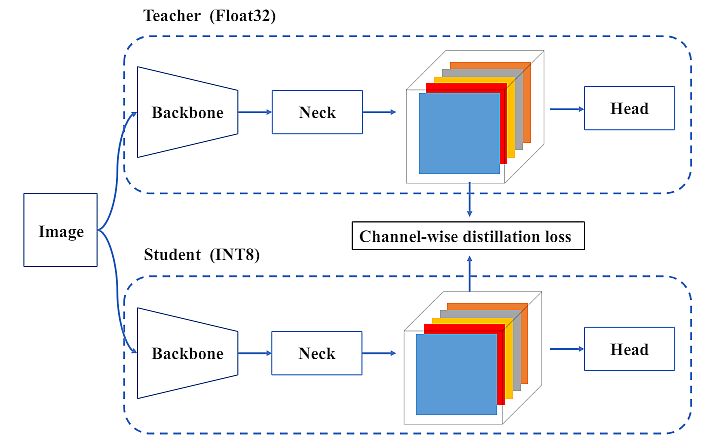
Quantization Outcomes
For industrial deployment, it has been a standard follow to use quantization to additional velocity up. Additionally, quantization won’t compromise the mannequin efficiency. Put up Coaching Quantization (PTQ) immediately quantizes the mannequin with solely a small calibration set.
Whereas Quantization Conscious Coaching (QAT) additional improves the efficiency with entry to the coaching set, it’s sometimes used collectively with distillation. Nevertheless, because of the heavy use of re-parameterization blocks in YOLOv6, earlier PTQ methods fail to supply excessive efficiency.
Due to the elimination of quantization-sensitive layers within the v2.0 launch, researchers immediately used full QAT on YOLOv6-S educated with RepOptimizer. Subsequently, it was onerous to include QAT when it got here to matching pretend quantizers throughout coaching and inference.
Researchers eradicated inserted quantizers via graph optimization to acquire larger accuracy and sooner velocity. Lastly, they in contrast the distillation-based quantization outcomes from PaddleSlim (desk under).
YOLOv6 – 2023 Replace
On this newest launch, the researchers renovated the community design and the coaching technique. They confirmed the comparability of YOLOv6 with different fashions at an analogous scale within the determine under. The brand new options of YOLOv6 embrace the next:
- They renewed the neck of the detector with a Bi-directional Concatenation (BiC) module to offer extra correct localization indicators. SPPF was simplified to type the SimCSPSPPF Block, which brings efficiency beneficial properties with negligible velocity degradation.
- They proposed an anchor-aided coaching (AAT) technique to take pleasure in some great benefits of each anchor-based and anchor-free paradigms with out touching inference effectivity.
- They deepened YOLOv6 to have one other stage within the spine and the neck. Subsequently, it achieved a brand new state-of-the-art efficiency on the COCO dataset at a high-resolution enter.
- They concerned a brand new self-distillation technique to spice up the efficiency of small fashions of YOLOv6, during which the heavier department for DFL is taken as an enhanced auxiliary regression department throughout coaching and is eliminated at inference to keep away from the marked velocity decline.
Researchers utilized characteristic integration at a number of scales as a essential and efficient element of object detection. They used a Function Pyramid Community (FPN) to combination the high-level semantic and low-level options through a top-down pathway, offering extra correct localization.
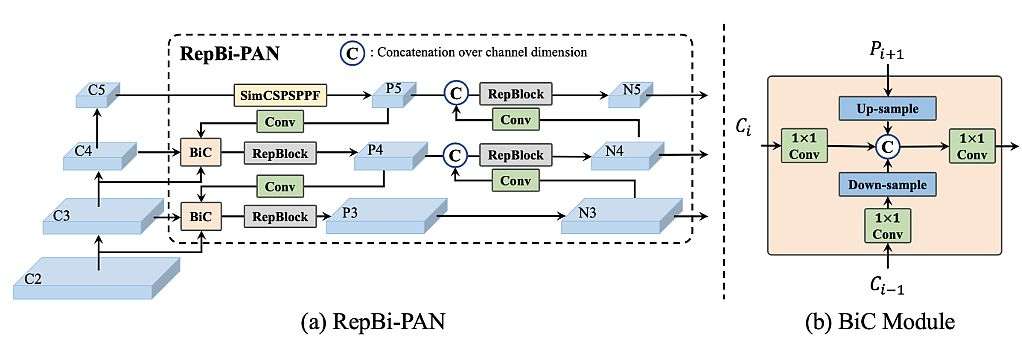
Additional Enhancements
Subsequently, different works on Bi-directional FPN improve the power of hierarchical characteristic illustration. PANet (Path Aggregation Community) provides an additional bottom-up pathway on high of FPN to shorten the data path of low-level and top-level options. That facilitates the propagation of correct indicators from low-level options.
BiFPN introduces learnable weights for various enter options and simplifies PAN to attain higher efficiency with excessive effectivity. They proposed PRB-FPN to retain high-quality options for correct localization by a parallel FP construction with bi-directional fusion and related enhancements.
Last Ideas on YOLOv6
The YOLO fashions are the usual in object detection strategies with their nice efficiency and huge applicability. Listed below are the conclusions about YOLOv6:
- Utilization: YOLOv6 is already in GitHub, so the customers can implement YOLOv6 shortly via the CLI and Python IDE.
- YOLOv6 duties: With real-time object detection and improved accuracy and velocity, YOLOv6 could be very environment friendly for trade functions.
- YOLOv6 contributions: YOLOv6’s major contribution is that it eliminates inserted quantizers via graph optimization to acquire larger accuracy and sooner velocity.
Listed below are some associated articles in your studying: