YOLOv8 is the latest mannequin within the YOLO algorithm sequence – probably the most well-known household of object detection and classification fashions within the Laptop Imaginative and prescient (CV) subject. With the newest model, the YOLO legacy lives on by offering state-of-the-art outcomes for picture or video analytics, with an easy-to-implement framework.
On this article, we’ll talk about:
- The evolution of the YOLO algorithms
- Enhancements and enhancements in YOLOv8
- Implementation particulars and suggestions
- Purposes
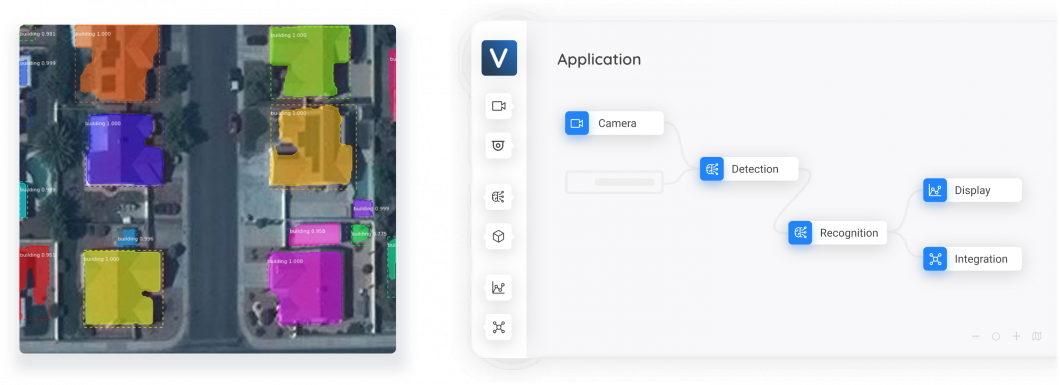
About us: Viso.ai affords the world’s main end-to-end Laptop Imaginative and prescient Platform Viso Suite. Our resolution helps a number of main organizations begin with pc imaginative and prescient and implement state-of-the-art fashions shortly and cheaply for numerous industrial functions. Get a demo.
What’s YOLO
You Solely Look As soon as (YOLO) is an object-detection algorithm launched in 2015 in a analysis paper by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. YOLO’s structure was a big revolution within the real-time object detection house, surpassing its predecessor – the Area-based Convolutional Neural Community (R-CNN).
YOLO is a single-shot algorithm that immediately classifies an object in a single cross by having just one neural community predict bounding containers and sophistication chances utilizing a full picture as enter.
The household YOLO mannequin is constantly evolving. A number of analysis groups have since launched completely different YOLO variations, with YOLOv8 being the newest iteration. The next part briefly overviews all of the historic variations and their enhancements.
A Transient Historical past of YOLO
Earlier than discussing YOLO’s evolution, let’s take a look at some fundamentals of how a typical object detection algorithm works.
The diagram under illustrates the important mechanics of an object detection mannequin.
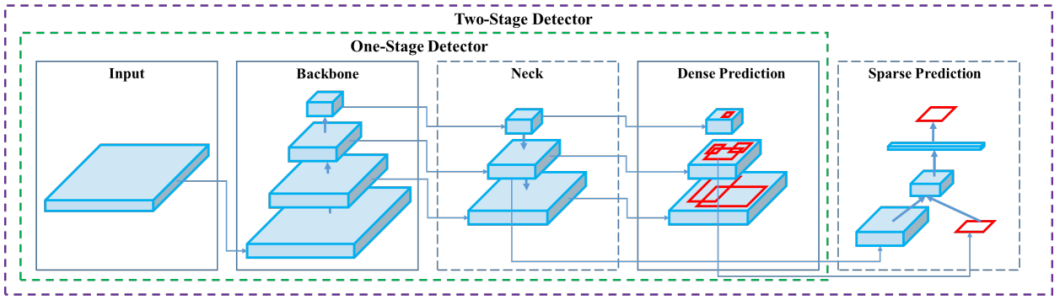
The structure consists of a spine, neck, and head. The spine is a pre-trained Convolutional Neural Community (CNN) that extracts low, medium, and high-level characteristic maps from an enter picture. The neck merges these characteristic maps utilizing path aggregation blocks just like the Function Pyramid Community (FPN). It passes them onto the top, classifying objects and predicting bounding containers.
The pinnacle can include one-stage or dense prediction fashions, comparable to YOLO or Single-shot Detector (SSD). Alternatively, it may well characteristic two-stage or sparse prediction algorithms just like the R-CNN sequence.
| Launch | Authors | Duties | Paper | |
|---|---|---|---|---|
| YOLO | 2015 | Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi | Object Detection, Primary Classification | You Solely Look As soon as: Unified, Actual-Time Object Detection |
| YOLOv2 | 2016 | Joseph Redmon, Ali Farhadi | Object Detection, Improved Classification | YOLO9000: Higher, Quicker, Stronger |
| YOLOv3 | 2018 | Joseph Redmon, Ali Farhadi | Object Detection, Multi-scale Detection | YOLOv3: An Incremental Enchancment |
| YOLOv4 | 2020 | Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao | Object Detection, Primary Object Monitoring | YOLOv4: Optimum Velocity and Accuracy of Object Detection |
| YOLOv5 | 2020 | Ultralytics | Object Detection, Primary Occasion Segmentation (through customized modifications) | no |
| YOLOv6 | 2022 | Chuyi Li, et al. | Object Detection, Occasion Segmentation | YOLOv6: A Single-Stage Object Detection Framework for Industrial Purposes |
| YOLOv7 | 2022 | Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao | Object Detection, Object Monitoring, Occasion Segmentation | YOLOv7: Trainable bag-of-freebies units new state-of-the-art for real-time object detectors |
| YOLOv9 | 2024 | Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao | Object Detection, Occasion Segmentation | YOLOv9: Studying What You Need to Study Utilizing Programmable Gradient Info |
| YOLOv10 | 2024 | Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, Guiguang Ding | Object Detection | YOLOv10: Actual-Time Finish-to-Finish Object Detection |
| YOLOv11 | 2024 | Ultralytics | Object Detection, Occasion Segmentation, Keypoint Estimation, Oriented Detection, Classification | no |
YOLOv1
As talked about, YOLO is a single-shot detection mannequin that improved upon the usual R-CNN detection mechanism with sooner and higher generalization efficiency.
The true change was how YOLOv1 framed the detection downside as a regression process to foretell bounding containers and sophistication chances from a single cross of a picture. The diagram under illustrates this level:
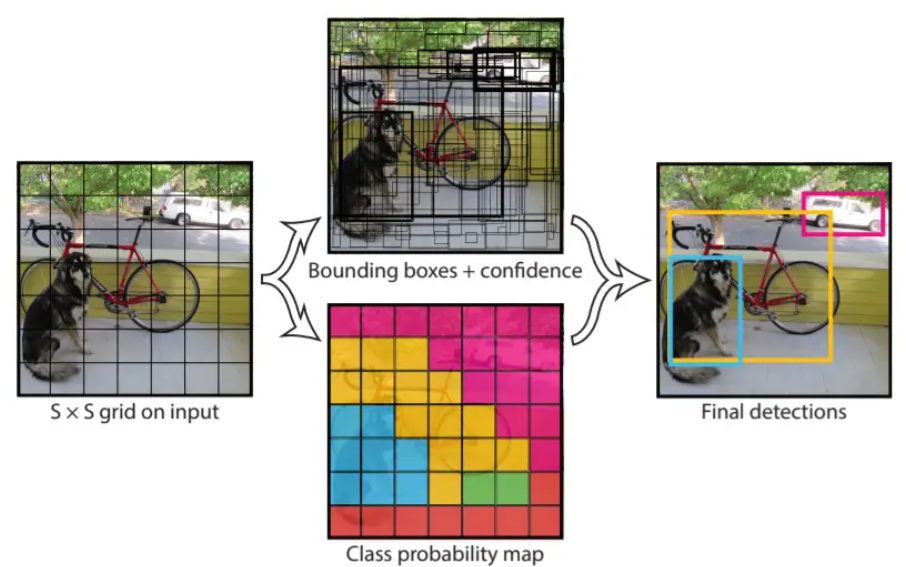
YOLO divides a picture into a number of grids and computes confidence scores and bounding containers for every grid cell that replicate the chance of an object situated inside a selected grid cell.
Subsequent, given the chance of an object being higher than zero, the algorithm computes respective class chances and multiplies them with the thing chances to generate an general chance rating and bounding field.
With this structure, YOLOv1 surpassed R-CNN with a imply common precision (mAP) of 63.4 and an inference pace of 45 frames per second (FPS) on the open supply Pascal Visible Object Lessons 2007 dataset.
YOLOv2
In 2016, Joseph Redmon and Ali Farhadi launched YOLOv2, which might detect over 9000 object classes. YOLOv2 launched anchor containers – predefined bounding containers referred to as priors that the mannequin makes use of to pin down the perfect place of an object.
The algorithm computes the Intersection over Union (IoU) scores for a predicted bounding field towards an anchor field. If the IOU reaches a threshold, the mannequin generates a prediction.
YOLOv2 achieved 76.8 mAP at 67 FPS on the VOC 2007 dataset.
YOLOv3
Joseph Redmon and Ali Farhadi revealed one other paper in 2018 to launch YOLOv3 that boasted greater accuracy than earlier variations, with an mAP of 28.2 at 22 milliseconds.
To foretell lessons, the YOLOv3 mannequin makes use of Darknet-53 because the spine with logistic classifiers as a substitute of softmax and Binary Cross-entropy (BCE) loss.
YOLOv4
In 2020, Alexey Bochkovskiy and different researchers launched YOLOv4, which launched the idea of a Bag of Freebies (BoF) and a Bag of Specials (BoS).
BoF is a gaggle of methods that enhance accuracy at no extra inference value. In distinction, BoS strategies improve accuracy considerably for a slight enhance in inference value.
BoF included CutMix, CutOut, Mixup knowledge augmentation methods, and a brand new Mosaic methodology. Mosaic augmentation mixes 4 completely different coaching photos to supply the mannequin with higher context data.
BoS strategies have options like non-linear activations and skip connections.
The mannequin achieved 43.5 mAP at roughly 65 FPS on the MS COCO dataset.
YOLOv5
With out an official analysis paper, Ultralytics launched YOLOv5 in June 2020, two months after the launch of YOLOv4. The mannequin is simple to coach and use since it’s a PyTorch implementation.
The structure makes use of a Cross-stage Partial (CSP) Connection block because the spine for a greater gradient circulate to cut back computational value.
Additionally, YOLOv5 makes use of the But One other Markup Language (YAML) information as a substitute of the CFG file that features mannequin configurations.
Since YOLOv5 lacks an official analysis paper, no genuine outcomes exist to check its efficiency with earlier variations and different object detection fashions.
YOLOv6
YOLOv6 is one other unofficial model of the YOLO sequence launched in 2022 by Meituan – a Chinese language procuring platform. The corporate focused the mannequin for industrial functions with higher efficiency than its predecessor.
The numerous variations embrace anchor-free detection and a decoupled head, which implies one head performs classification. In distinction, the opposite conducts regression to foretell bounding field coordinates.
The adjustments resulted in YOLOv6(nano) reaching an mAP of 37.5 at 1187 FPS on the COCO dataset and YOLOv6(small) reaching 45 mAP at 484 FPS.
YOLOv7
In July 2022, a gaggle of researchers launched the open-source mannequin YOLOv7, the quickest and probably the most correct object detector with an mAP of 56.8% at FPS starting from 5 to 160.
Prolonged Environment friendly Layer Aggregation Community (E-ELAN) types the spine of YOLOv7, which improves coaching by letting the mannequin study numerous options with environment friendly computation.
Additionally, the mannequin makes use of compound scaling for concatenation-based fashions to deal with the necessity for various inference speeds.
YOLOv8
We lastly come to Ultralytics YOLOv8, launched in January 2023. Like v5 and v6, YOLOv8 has no official paper however boasts greater accuracy and sooner pace.
As an illustration, the YOLOv8(medium) has a 50.2 mAP rating at 1.83 milliseconds on the COCO dataset and A100 TensorRT.
YOLO v8 additionally includes a Python bundle and CLI-based implementation, making it simple to make use of and develop.
Let’s look intently at what the YOLOv8 can do and discover a number of of its vital developments.
Since YOLOv8’s launch, two completely different groups of researchers have launched YOLOv9 (February 2024) and YOLOv10 (Could 2024).
YOLOv8 Duties
YOLOv8 is available in 5 variants based mostly on the variety of parameters – nano(n), small(s), medium(m), giant(l), and additional giant(x). You need to use all of the variants for classification, object detection, and segmentation.
Picture Classification
Classification includes categorizing a complete picture with out localizing the thing current throughout the picture.
You may implement classification with YOLOv8 by including the -cls suffix to the YOLOv8 model. For instance, you should use yolov8n-cls.pt for classification if you happen to want to use the nano model.
Object Detection
Object detection localizes an object inside a picture by drawing bounding containers. You don’t have so as to add any suffix to make use of YOLOv8 for detection.
The implementation solely requires you to outline the mannequin as yolov8n.pt for object detection with the nano variant.
Picture Segmentation
Picture segmentation goes a step additional and identifies every pixel belonging to an object. In contrast to object detection, segmentation is extra exact in finding completely different objects inside a single picture.
You may add the -seg suffix as yolov8n-seg.pt to implement segmentation with the YOLOv8 nano variant.
YOLOv8 Main Developments
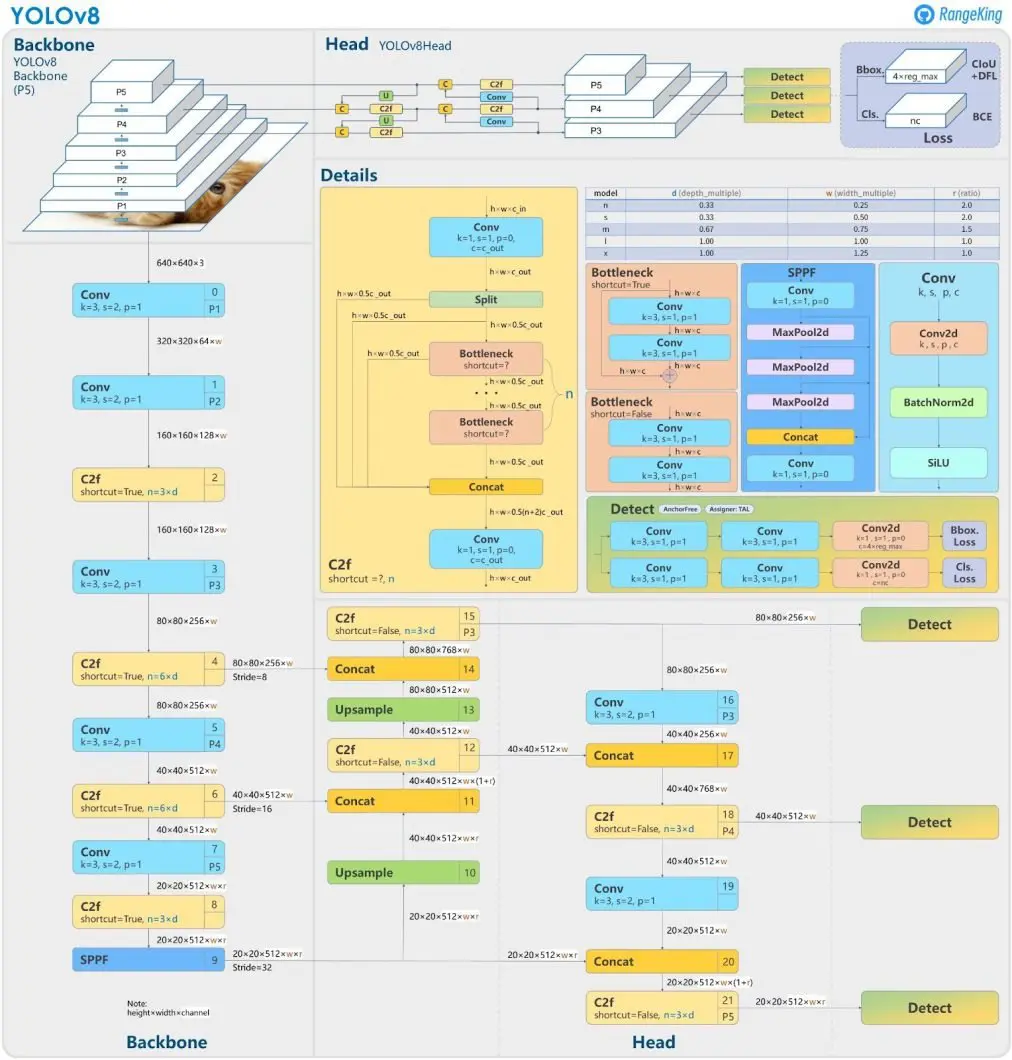
The principle options of YOLOv8 embrace mosaic knowledge augmentation, anchor-free detection, a C2f module, a decoupled head, and a modified loss perform.
Let’s talk about every change in additional element.
Mosaic Knowledge Augmentation
Like YOLOv4, YOLOv8 makes use of mosaic knowledge augmentation that mixes 4 photos to supply the mannequin with higher context data. The change in YOLOv8 is that the augmentation stops within the final ten coaching epochs to enhance efficiency.
Anchor-Free Detection
YOLOv8 switched to anchor-free detection to enhance generalization. The issue with anchor-based detection is that predefined anchor containers scale back the educational pace for customized datasets.
With anchor-free detection, the mannequin immediately predicts an object’s mid-point and reduces the variety of bounding field predictions. This helps pace up Non-max Suppression (NMS) – a pre-processing step that discards incorrect predictions.
C2f Module
The mannequin’s spine now consists of a C2f module as a substitute of a C3 one. The distinction between the 2 is that in C2f, the mannequin concatenates the output of all bottleneck modules. In distinction, in C3, the mannequin makes use of the output of the final bottleneck module.
A bottleneck module consists of bottleneck residual blocks that scale back computational prices in deep studying networks.
This accelerates the coaching course of and improves gradient circulate.
Decoupled Head
The diagram above illustrates that the top not performs classification and regression collectively. As a substitute, it performs the duties individually, which will increase mannequin efficiency.
Loss
Misalignment is feasible because the decoupled head separates the classification and regression duties. It means the mannequin might localize one object whereas classifying one other.
The answer is to incorporate a process alignment rating based mostly on which the mannequin is aware of a constructive and unfavourable pattern. The duty alignment rating multiplies the classification rating with the Intersection over Union (IoU) rating. The IoU rating corresponds to the accuracy of a bounding field prediction.
Based mostly on the alignment rating, the mannequin selects the top-k constructive samples and computes a classification loss utilizing BCE and regression loss utilizing Full IoU (CIoU) and Distributional Focal Loss (DFL).
The BCE loss merely measures the distinction between the precise and predicted labels.
The CIoU loss considers how the anticipated bounding field is relative to the bottom reality when it comes to the middle level and side ratio. In distinction, the distributional focal loss optimizes the distribution of bounding field boundaries by focusing extra on samples that the mannequin misclassifies as false negatives.
YOLOv8 Implementation
Let’s see how one can implement YOLOv8 in your native machine for object detection. The advantage of YOLOv8 is that Ultralytics permits you to apply the mannequin immediately by way of the CLI and as a Python bundle.
CLI Implementation
You can begin utilizing the mannequin by operating pip set up ultralytics within the Anaconda command immediate.
After set up, you’ll be able to run the next command, which trains the YOLOv8 nano mannequin on the COCO dataset with ten coaching epochs and a studying price of 0.01.
yolo prepare knowledge=coco128.yaml mannequin=yolov8n.pt epochs=10 lr0=0.01
You may view the CLI syntax for different operations on the Ultralytics CLI information.
Python Implementation
The instance under reveals how one can shortly fine-tune the YOLOv8 nano mannequin on a customized dataset for object detection.
The info used comes from the Open Photos Dataset v7 for object detection. The pictures include geese with bounding field labels.
The publicly out there pattern for fine-tuning is on Kaggle, which comprises 400 coaching and 50 validation photos. The bounding field labels include x-y coordinates.
You may comply with alongside the steps utilizing the Google Colab pocket book.
Step 1
Step one is to put in the Ultralytics bundle.
!pip set up ultralytics
Step 2
Subsequent, we are going to import the related packages.
from ultralytics import YOLO
from google.colab import information
Step 3
Then, we are going to import our dataset utilizing the Kaggle API. You could create an account on Kaggle to get your distinctive API key and obtain the associated Kaggle JSON file.
As soon as the JSON file is in your native machine, you’ll be able to add it on Colab utilizing the next:
information.add()
A immediate will ask you to add the file out of your native machine.
You may run the next instructions to mount the info in your Google Drive.
!rm -r ~/.kaggle
!mkdir ~/.kaggle
!mv ./kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle datasets obtain -d haziqasajid5122/yolov8-finetuning-dataset-ducks
!unzip yolov8-finetuning-dataset-ducks -d /content material/Knowledge
!cp /content material/Knowledge/config.yaml /content material/config.yaml
YAML is the usual YOLO dataset format. In our case, it’s the file: config.yaml
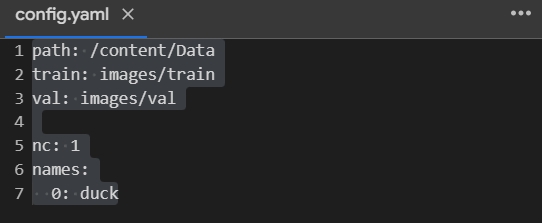
In our case, there’s only one class, “duck.”
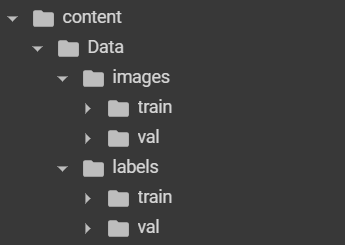
There could be a further folder for the check set.
Step 4
Load the YOLOv8 nano mannequin as follows:
mannequin = YOLO("yolov8n.pt")
Step 5
Fantastic-tune the mannequin with the next command:
outcomes = mannequin.prepare(knowledge="/content material/config.yaml", epochs=20)
It will prepare the YOLOv8 mannequin on 20 coaching epochs. You may outline additional hyperparameters based mostly in your necessities.
You could guarantee you choose a T4 GPU for sooner coaching.
Step 6
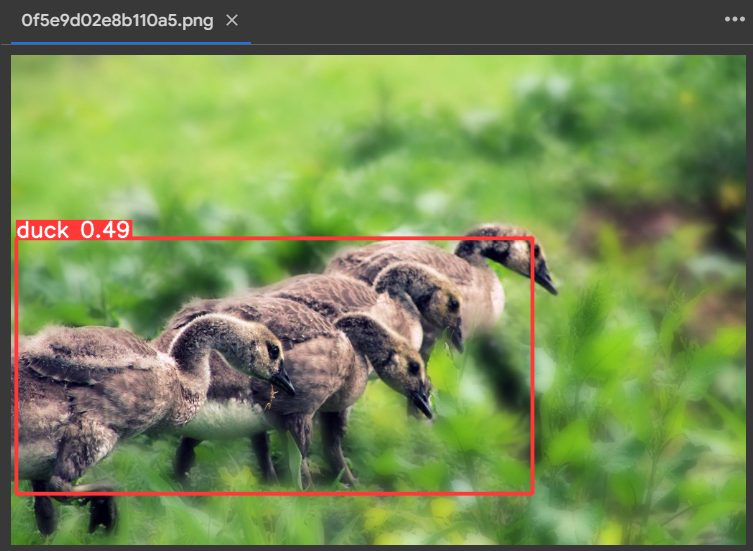
You may load the very best mannequin and run your predictions on a picture.
infer = YOLO("/content material/runs/detect/train32/weights/greatest.pt")
outcomes = infer.predict("/content material/Knowledge/photos/val/0f5e9d02e8b110a5.png", save=True)
Step 7
You may view the picture’s predicted bounding field and classification rating by going to “content material/runs/detect/predict” from the left menu bar. It offers the next consequence:

YOLOv8 Purposes
YOLOv8 is a flexible mannequin that you should use in a number of real-world functions. Beneath are a number of well-liked use instances.
- Individuals counting: Retailers can prepare the mannequin to detect real-time foot visitors of their outlets, detect queue size, and extra.
- Sports activities analytics: Analysts can use the mannequin to trace participant actions in a sports activities subject to assemble related insights concerning staff dynamics (See AI in sports activities).
- Stock administration: The thing detection mannequin might help detect product stock ranges to make sure enough inventory ranges and supply data concerning shopper conduct.
- Autonomous automobiles: Autonomous driving makes use of object detection fashions to assist navigate self-driving vehicles safely by way of the street.

YOLOv8: Key Takeaways
The YOLO sequence is the usual within the object detection house with its exemplary efficiency and broad applicability. Right here are some things you need to bear in mind about YOLOv8.
- YOLOv8 enhancements: YOLOv8’s main enhancements embrace a decoupled head with anchor-free detection and mosaic knowledge augmentation that turns off within the final ten coaching epochs.
- YOLOv8 duties: Moreover real-time object detection with cutting-edge pace and accuracy, YOLOv8 is environment friendly for classification and segmentation duties.
- Ease-of-use: With an easy-to-use bundle, customers can implement YOLOv8 shortly by way of the CLI and Python IDE.
You may learn associated subjects within the following articles:
Actual-Life Laptop Imaginative and prescient for Enterprise
Whereas implementing YOLOv8 in isolation is fast and straightforward for high-performance object detection duties. Nevertheless, utilizing it in a full-fledged pc imaginative and prescient system and business-critical functions is a large problem.
Viso.ai might help you implement pc imaginative and prescient fashions in an end-to-end pc imaginative and prescient system by way of the Viso Suite that integrates merely with the mannequin frameworks.
The Viso pc imaginative and prescient platform can also be helpful in serving to you annotate knowledge within the required format to be used in YOLO fashions, prepare customized YOLO fashions, and deploy them at scale.
Request a demo to see how your staff can remedy advanced enterprise issues with pc imaginative and prescient.